Developing a Deep Learning Application
This project demonstrates development of a Python command-line application that uses a deep neural network to predict the contents of images. The application enables the user to train the network on a set of arbitrary, labeled images and to use that trained network to predict the labels of new images.
During development, the network managed 78.4% accuracy on a dataset consisting of images of 102 different types of flowers.
This is page 1 of 3 for the project, where I
Iteratively Train and Test the Classifer in a Notebook
The specific tasks break down as follows:
- Load and Transform the Images.
- Train the Classifier, saving the classifier state after each training epoch.
- Choose the Optimal Epoch after examining training data.
- Load the Classifier State for that top-performing version of the classifier.
- Test the Top-Performing Epoch on the test set.
- Use the Network for Inference.
Load and Transform the Images
import torch
from torch import nn, optim
from torchvision import transforms, datasets, models
import json
import time
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from PIL import Image
%matplotlib inline
data_dir = '/home/ryan/large-files/datasets/flowers'
Define the image transforms. Note the validations images have the test_transforms applied (so, no random rotation/cropping/flipping).
train_transforms = transforms.Compose([transforms.RandomRotation(30),
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
test_transforms = transforms.Compose([transforms.Resize(255),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
train_data = datasets.ImageFolder(data_dir + '/train',
transform=train_transforms)
valid_data = datasets.ImageFolder(data_dir + '/valid',
transform=test_transforms)
test_data = datasets.ImageFolder(data_dir + '/test',
transform=test_transforms)
Keep the mapping from the index (order opened by ImageFolder) to the class (folder name).
class_num_to_idx = train_data.class_to_idx
idx_to_class_num = {v:k for k, v in class_num_to_idx.items()}
dict(list(idx_to_class_num.items())[:5])
{0: '1', 1: '10', 2: '100', 3: '101', 4: '102'}
batch_size = 48
trainloader = torch.utils.data.DataLoader(train_data,
batch_size=batch_size,
shuffle=True)
validloader = torch.utils.data.DataLoader(valid_data,
batch_size=batch_size)
testloader = torch.utils.data.DataLoader(test_data,
batch_size=batch_size)
train_batches = trainloader.__len__()
valid_batches = validloader.__len__()
test_batches = testloader.__len__()
image_count = (train_batches + valid_batches + test_batches) * batch_size
print('trainloader batches: {}'.format(train_batches))
print('validloader batches: {}'.format(valid_batches))
print(' testloader batches: {}\n'.format(test_batches))
print(' total images: {}'.format(image_count))
trainloader batches: 137
validloader batches: 18
testloader batches: 18
total images: 8304
The file counts from the bash scripts below are the correct counts of images in the training set. The counts from the previous cell assume that every batch contains 32 images, which is not the case for the last batch in each trainloader, which is partially full.
!find /home/ryan/large-files/datasets/flowers/train -type f | wc -l
!find /home/ryan/large-files/datasets/flowers/valid -type f | wc -l
!find /home/ryan/large-files/datasets/flowers/test -type f | wc -l
6552
818
819
Total images: 6552 + 818 + 819 = 8189.
The following captures a single batch.
images, labels = next(iter(trainloader))
print('images shape: {}'.format(images.shape))
print('labels shape: {}'.format(labels.shape))
images shape: torch.Size([48, 3, 224, 224])
labels shape: torch.Size([48])
- The
imagestensor containsbatch_sizeimages and is a three color channel, 224x224 pixel image. - The
labelstensor contains a list of integer indexes corresponding to what kind of flower is represented in the image.
Load the Class Mapping
Next, load a mapping from class number to category. This JSON object gives a dictionary mapping the integer-encoded category to the actual names of flowers.
with open('/home/ryan/large-files/datasets/flowers/cat_to_name.json') as f:
class_num_to_name = json.load(f)
dict(list(class_num_to_name.items())[:3])
{'21': 'fire lily', '3': 'canterbury bells', '45': 'bolero deep blue'}
images, labels = next(iter(testloader))
index = labels[0].item()
class_num = idx_to_class_num[index]
name = class_num_to_name[class_num]
print('label item (index): {}'.format(index))
print(' class number: {}'.format(class_num))
print(' category: {}'.format(name))
label item (index): 0
class number: 1
category: pink primrose
Print Some Examples
def imshow(image, ax=None, title=None, normalize=True):
"""Imshow for Tensor."""
if ax is None:
fig, ax = plt.subplots()
image = image.numpy().transpose((1, 2, 0))
if normalize:
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
image = np.clip(image, 0, 1)
ax.imshow(image)
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.tick_params(axis='both', length=0)
ax.set_xticklabels('')
ax.set_yticklabels('')
return ax
for loader_str, loader in [('Training', trainloader),
('Validation', validloader),
('Testing', testloader)]:
data_iter = iter(loader)
images, labels = next(data_iter)
ncol = 5
fig, axes = plt.subplots(figsize=(16,4),
ncols=ncol)
for ii in range(ncol):
ax = axes[ii]
imshow(images[ii],
ax=ax,
normalize=True)
index = labels[ii].item()
class_num = idx_to_class_num[index]
name = class_num_to_name[class_num]
ax.set_title('{} {}: {}'.format(loader_str, class_num, name))



Build and Train the Classifier
model = models.vgg11(pretrained=True)
model
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(3): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): ReLU(inplace=True)
(5): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(6): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): ReLU(inplace=True)
(8): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): ReLU(inplace=True)
(10): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(11): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): ReLU(inplace=True)
(13): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(14): ReLU(inplace=True)
(15): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(16): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(17): ReLU(inplace=True)
(18): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(19): ReLU(inplace=True)
(20): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Freeze parameters so we don’t backprop through them.
for param in model.parameters():
param.requires_grad = False
Create a new classifier with the appropriate number of classes for the dataset: 102.
model.classifier = nn.Sequential(nn.Linear(25088, 4096),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(4096, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 102),
nn.LogSoftmax(dim=1))
Set optimizer to only train the classifier parameters. Send the model to the GPU.
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.classifier.parameters(), lr=0.003)
device = 'cuda'
model.to(device);
Helper function to save the state of the model after each epoch.
def save_classifier_state(e):
filepath = ('/home/ryan/large-files/saved-models/classifier_state_epoch_{}.pth'
.format(str(e)
.zfill(2)))
torch.save(model.classifier.state_dict(),
filepath)
Function that handles training of the network.
def train_network(epochs, step_increment, print_table):
if print_table == True:
print('Epoch\tStep\tTraining Loss\tValidation Loss\t\tValidation Accuracy\tElapsed Time')
step = 1
# Capture Start Time
start_time = time.time()
epoch_index, step_index = [], []
train_losses, valid_losses, accuracies, elapsed = [], [], [], []
for e in range(epochs):
train_loss, train_count, valid_loss, valid_count = 0, 0, 0, 0
for inputs, labels in trainloader:
# Model in training mode, dropout is on
model.train()
# Move input and label tensors to the default device
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
output = model.forward(inputs)
loss = criterion(output, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_count += len(inputs)
if step % step_increment == 0 or step == 1 or step == len(trainloader) :
# Turn off gradients for validation, will speed up inference
with torch.no_grad():
# Model in inference mode, dropout is off
model.eval()
accuracy = 0
equals_list = []
for inputs, labels in validloader:
inputs, labels = inputs.to(device), labels.to(device)
logps = model.forward(inputs)
batch_loss = criterion(logps, labels)
valid_loss += batch_loss.item()
valid_count += len(inputs)
# Calculate accuracy
ps = torch.exp(logps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
equals_list.extend(equals.cpu().numpy().ravel())
# Calculate Elapsed Time
elapsed_time = time.time() - start_time
epoch_index.append(e+1)
step_index.append(step)
train_losses.append(train_loss / train_count)
valid_losses.append(valid_loss / valid_count)
accuracies.append(sum(equals_list) / len(equals_list))
elapsed.append(elapsed_time)
if print_table == True and step == 137:
print("{:3}/{}\t{:4}\t{:13.3f}\t\t{:7.3f}\t\t\t{:11.3f}\t{:12.1f}"
.format(e+1, epochs,
step,
train_losses[-1],
valid_losses[-1],
accuracies[-1],
elapsed[-1]))
train_loss, train_count, valid_loss, valid_count = 0, 0, 0, 0
step += 1
# Reset Step Counter for New Epoch
step = 1
save_classifier_state(e+1)
training_data = pd.DataFrame(list(zip(epoch_index, step_index, train_losses,
valid_losses, accuracies, elapsed)),
columns=['Epoch','Step','Training Loss',
'Validation Loss','Accuracy','Elapsed'])
training_data.index += 1
return training_data
train_anew = False
if train_anew:
epoch_count = 30
step_increment = 20
training_data = train_network(epoch_count,
step_increment,
True)
%%bash
cd /home/ryan/large-files/saved-models/
ls -lh
total 12G
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:39 classifier_state_epoch_01.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:41 classifier_state_epoch_02.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:43 classifier_state_epoch_03.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:44 classifier_state_epoch_04.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:46 classifier_state_epoch_05.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:47 classifier_state_epoch_06.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:49 classifier_state_epoch_07.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:51 classifier_state_epoch_08.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:52 classifier_state_epoch_09.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:54 classifier_state_epoch_10.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:55 classifier_state_epoch_11.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:57 classifier_state_epoch_12.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 14:59 classifier_state_epoch_13.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:00 classifier_state_epoch_14.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:02 classifier_state_epoch_15.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:03 classifier_state_epoch_16.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:05 classifier_state_epoch_17.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:06 classifier_state_epoch_18.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:08 classifier_state_epoch_19.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:10 classifier_state_epoch_20.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:11 classifier_state_epoch_21.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:13 classifier_state_epoch_22.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:14 classifier_state_epoch_23.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:16 classifier_state_epoch_24.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:18 classifier_state_epoch_25.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:19 classifier_state_epoch_26.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:21 classifier_state_epoch_27.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:22 classifier_state_epoch_28.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:24 classifier_state_epoch_29.pth
-rw-r--r-- 1 ryan ryan 401M Jul 3 15:25 classifier_state_epoch_30.pth
Choose the Optimal Epoch
The optimal training epoch to use is the one just before the validation error begins increasing.
Define a helper function to print losses and accuracies.
def plot_losses_and_accuracies(training_data):
fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(nrows=2, ncols=2, figsize=(16,16))
row_1_x_axis_label = 'Training Batches Completed'
ax1.set_title('Losses')
ax1.plot(training_data['Training Loss'], label='Training loss')
ax1.plot(training_data['Validation Loss'], label='Validation loss')
ax1.set_xlabel(row_1_x_axis_label)
ax1.set_ylim(bottom=0)
ax2.set_title('Accuracy')
ax2.plot(training_data['Accuracy'], label='Accuracy')
ax2.set_xlabel(row_1_x_axis_label)
ax2.set_ylim(0,1)
row_2_x_axis_label = 'Training Epochs Completed'
training_epoch_data = training_data[training_data['Step']==137].reset_index(drop=True)
training_epoch_data.index += 1
ax3.set_title('Losses')
ax3.plot(training_epoch_data['Training Loss'], label='Training loss')
ax3.plot(training_epoch_data['Validation Loss'], label='Validation loss')
ax3.set_xlabel(row_2_x_axis_label)
ax3.set_ylim(bottom=0)
ax4.set_title('Accuracy')
ax4.plot(training_epoch_data['Accuracy'], label='Accuracy')
ax4.set_xlabel(row_2_x_axis_label)
ax4.set_ylim(0,1)
for ax in [ax1, ax2, ax3, ax4]:
ax.legend(frameon=False)
for spine in ax.spines.values():
spine.set_visible(False)
if train_anew:
training_data.to_csv('/home/ryan/repos/image-classifier/last-results.csv')
else: # Load training data from previous results
training_data = (pd.read_csv('/home/ryan/repos/image-classifier/last-results.csv',
index_col=0))
training_data = training_data[training_data['Step']!=1].reset_index(drop=True)
training_epoch_data = training_data[training_data['Step']==137].reset_index(drop=True)
training_epoch_data.index += 1
training_epoch_data.head()
| Epoch | Step | Training Loss | Validation Loss | Accuracy | Elapsed | |
|---|---|---|---|---|---|---|
| 1 | 1 | 137 | 0.052876 | 0.035098 | 0.544010 | 96.448691 |
| 2 | 2 | 137 | 0.045848 | 0.026634 | 0.651589 | 194.136987 |
| 3 | 3 | 137 | 0.041181 | 0.024728 | 0.677262 | 289.785085 |
| 4 | 4 | 137 | 0.039035 | 0.025416 | 0.695599 | 385.474752 |
| 5 | 5 | 137 | 0.040536 | 0.021961 | 0.722494 | 480.712682 |
plot_losses_and_accuracies(training_data)
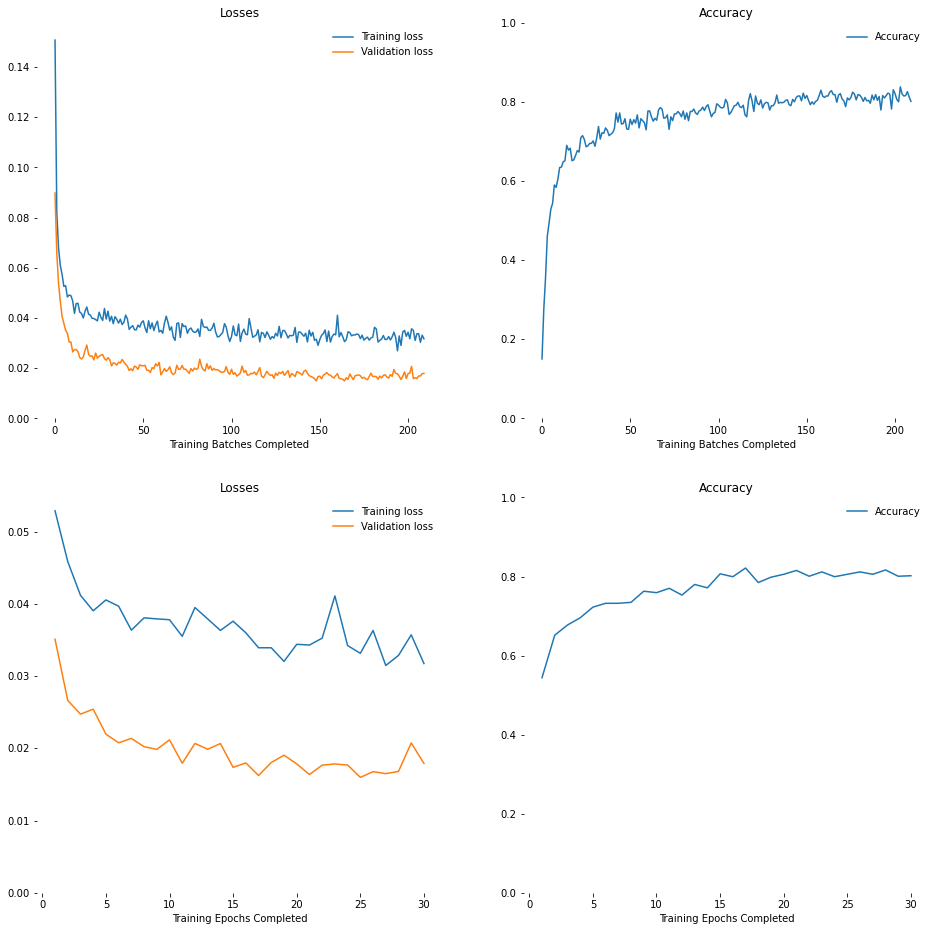
Load the Classifier State for the Top-Performing Epoch
training_epoch_data[training_epoch_data['Accuracy']==training_epoch_data['Accuracy'].max()]
| Epoch | Step | Training Loss | Validation Loss | Accuracy | Elapsed | |
|---|---|---|---|---|---|---|
| 17 | 17 | 137 | 0.033916 | 0.016235 | 0.821516 | 1624.072668 |
def load_checkpoint(epoch):
filepath = ('/home/ryan/large-files/saved-models/classifier_state_epoch_{}.pth'
.format(str(epoch).zfill(2)))
checkpoint = torch.load(filepath)
classifier = nn.Sequential(nn.Linear(25088, 4096),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(4096, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 102),
nn.LogSoftmax(dim=1))
classifier.load_state_dict(checkpoint)
return classifier
model = models.vgg11(pretrained=True)
model.classifier = load_checkpoint(17) # Epoch 17 was top-performing
device = 'cuda'
model.to(device);
Test the Top-Performing Epoch on the Test Set
The model has only been exposed to the training and validation sets so far; it has not seen the test set.
with torch.no_grad():
# Model in inference mode, dropout is off
model.eval()
for loader_name, loader in [(' Train set accuracy', trainloader),
('Validation set accuracy', validloader),
(' Test set accuracy', testloader)]:
equals_list = []
for inputs, labels in loader:
inputs, labels = inputs.to(device), labels.to(device)
logps = model.forward(inputs)
# Calculate accuracy
ps = torch.exp(logps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
equals_list.extend(equals.cpu().numpy().ravel())
print('{}: {:2.1%}'.format(loader_name, (sum(equals_list) / len(equals_list))))
Train set accuracy: 72.9%
Validation set accuracy: 82.2%
Test set accuracy: 78.4%
Use Trained Network for Inference
Define a helper function to preprocess an image.
Uses the image module of the PIL library. Scales, crops, and normalizes a PIL image, then converts it to a Numpy array tensor. Following this preprocessing, it is ready for use in PyTorch.
def process_image(image_path):
img = Image.open(image_path)
# Resize Image so shortest side is a specified length
short_side = 256
width, height = img.size
resize_ratio = max(short_side/width, short_side/height)
newsize = int(resize_ratio*width), int(resize_ratio*height)
resized_img = img.resize(newsize)
# Crop Image to Center 224x224
center_size = 224
left = int((newsize[0]-center_size)/2)
right = left + center_size
upper = int((newsize[1]-center_size)/2)
lower = upper + center_size
cropped_img = resized_img.crop((left, upper, right, lower))
# Encode color channels as floats (0-1) instead of integers (0-255)
np_image = np.array(cropped_img)/255.
# Normalize colors
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
normalized_image = (np_image - mean)/std
# Convert each image from (224, 224, 3) to (3, 224, 224)
# PyTorch expects the color channel to be first, but is last
processed_image = normalized_image.transpose((2, 0, 1))
return processed_image
The following undoes the processing of process_image and displays the image in the notebook.
def imshow(image, ax=None, title=None):
"""Imshow for Tensor."""
if ax is None:
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(16,9))
# PyTorch tensors assume the color channel is the first dimension
# but matplotlib assumes is the third dimension
image = image.transpose((1, 2, 0))
# Undo preprocessing
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
image = std * image + mean
# Image needs to be clipped between 0 and 1 or it looks like noise when displayed
image = np.clip(image, 0, 1)
ax1.imshow(image)
ax1.tick_params(
axis='x',
bottom=False,
labelbottom=False)
ax1.tick_params(
axis='y',
left=False,
labelleft=False)
return (ax1, ax2)
Class Prediction
def predict(image_path, model, topk=5):
image = process_image(image_path)
image = torch.from_numpy(image)
image = image.view(1, 3, 224, 224) # Reshape from [3, 224, 224] to [1, 3, 224, 224]
image = image.to('cuda',
dtype=torch.float)
logps = model.forward(image)
ps = torch.exp(logps)
top_p, top_class = ps.topk(topk, dim=1)
return top_p, top_class
Run Predictions on Some Sample Impages
def print_likelihood(image_path):
# Show the Image
ax1, ax2 = imshow(process_image(image_path))
# Print the Probabilities
probabilities, classes = predict(image_path, model, 5)
index = classes[0][0].item()
class_num = idx_to_class_num[index]
name = class_num_to_name[class_num]
ax1.set_title(name)
names, probs = [], []
for c, p in zip(classes[0], probabilities[0]):
index = c.item()
class_num = idx_to_class_num[index]
name = class_num_to_name[class_num]
names.append(name)
probs.append(p.item())
pos = np.arange(len(names))
names = [n.replace(' ','\n') for n in names]
probs = [int(round(p*100.,0)) for p in probs]
barlist = ax2.bar(pos,
probs,
align='center',
color='grey')
barlist[0].set_color('navy')
plt.xticks(pos,
names,
alpha=0.8)
plt.ylabel('% Confidence',
alpha=0.8)
plt.ylim(0,100)
for spine in plt.gca().spines.values():
spine.set_visible(False)
rects = plt.gca().patches
for rect, label in zip(rects, probs):
height = rect.get_height()
plt.gca().text(rect.get_x() + rect.get_width() / 2,
height + 1,
str(label)+'%',
ha='center',
va='bottom',
color='black')
image_paths = ['/home/ryan/repos/image-classifier/single-images/test_9_image_06413.jpg',
'/home/ryan/repos/image-classifier/single-images/train_26_image_06509.jpg',
'/home/ryan/repos/image-classifier/single-images/train_60_image_02941.jpg',
'/home/ryan/repos/image-classifier/single-images/valid_82_image_01683.jpg',
'/home/ryan/repos/image-classifier/single-images/valid_92_image_03065.jpg']
print_likelihood(image_paths[0])

print_likelihood(image_paths[1])
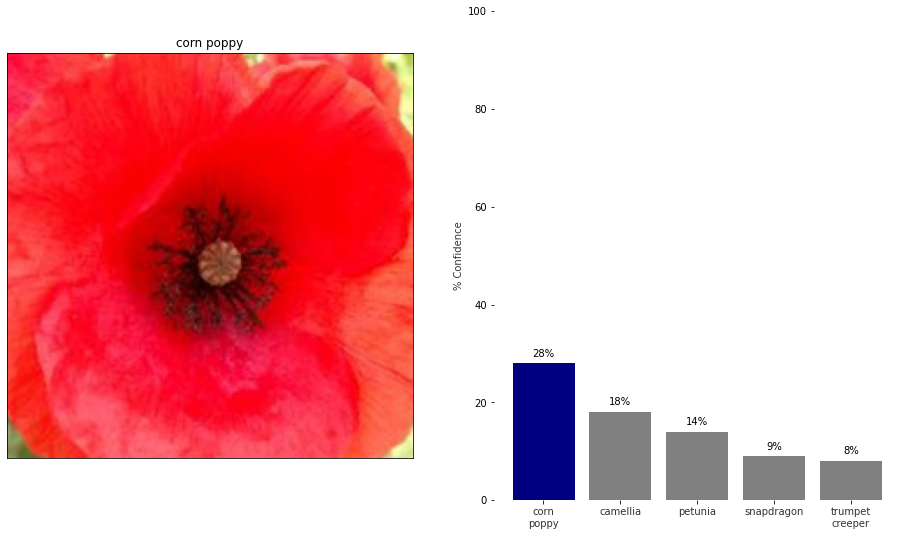
print_likelihood(image_paths[2])

print_likelihood(image_paths[3])

print_likelihood(image_paths[4])
