Fundamental Concepts and Definitions
- Instance or Sample: a single row in a dataset that corresponds to a single example of the concept or object being examined.
- Feature Representation: converting a real world concept or object of interest and converting it into a set of numbers that the computer can understand. For example, a piece of fruit might be represented by
mass,width,height, andcolor_score. These are the aspects that will be used as inputs to the predictor. Represented by $X$. - Label: the target class, in the case of classification, or the target particular continuous value, in the case of regression. Represented by $y$.
- Training Set: a partition, 75% by default, of the original dataset that is used estimate the parameters for a model, or “fit the estimator.” Represented by $X_{train}$ and $y_{train}$.
- Test Set: a partition, 25% by default, of the original dataset that is used to estimate the accuracy of the estimator on new data. Represented by $X_{test}$ and $y_{test}$.
- Estimator: an object in Scikit-Learn that can be a classifier or a regressor. The goal of this estimator, or more generally, “model,” is to learn how to classify or predict target values for new data instances.
- Model: a specific mathematical or computational description that expresses the relationship between a set of input variables and one or more outcome variables that are being studied or predicted.
- Model Fitting: the process of passing in a training set to learn parameters that are internal to the estimator. The result of model fitting is a “trained model.”
Types of Supervised Learning:
-
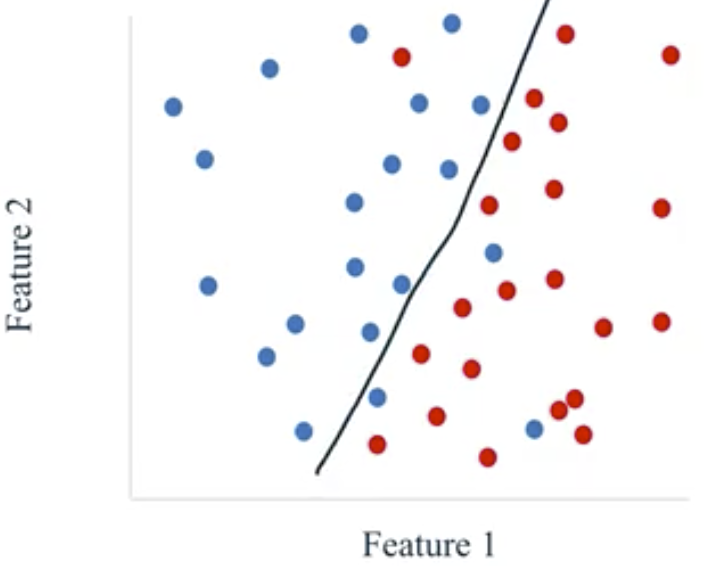
Classification: target value is a discrete class value. Classification subtypes:
- Binary Classification: target value is either of two categories, often output by the estimator as 0 or 1.
- Multi-Class Classification: target value is one of a set of more than two discrete values.
- Multi-Label Classification: classification for which each instance is given multiple labels.
-
Regression: target value is a continuous value.
Generalization, Overfitting, and Underfitting
- Generalization Ability: refers to an algorithm’s ability to give accurate predictions for new, previously unseen data, specifically the test set.
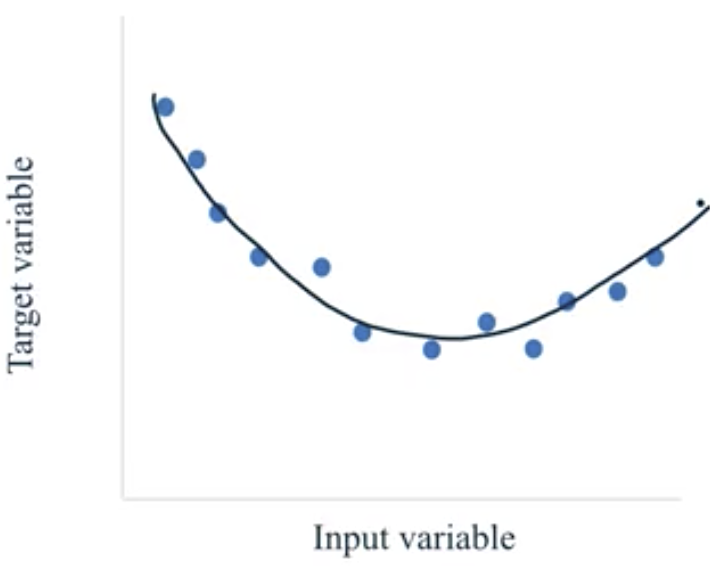
- Overfit: models that are too complex for the amount of training data available and therefore not likely to generalize well to new examples. These models do not perform well on the test data.
- Often, this occurs when a complex model is fit with an inadequate amount of training data.
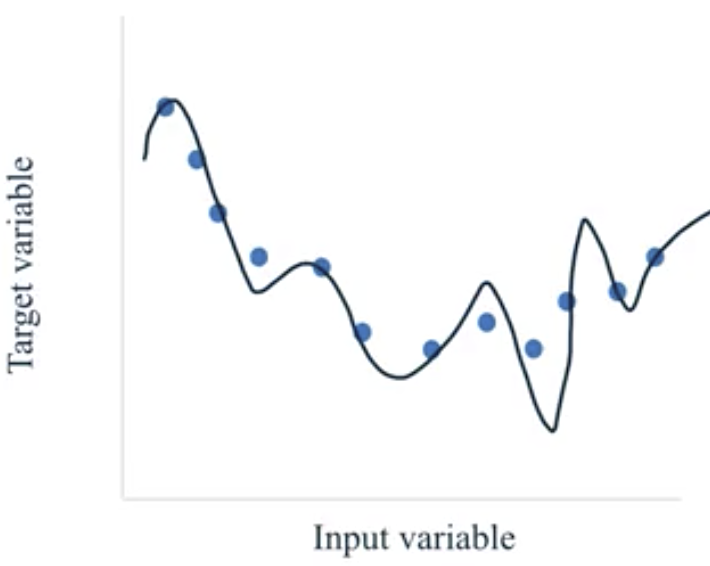
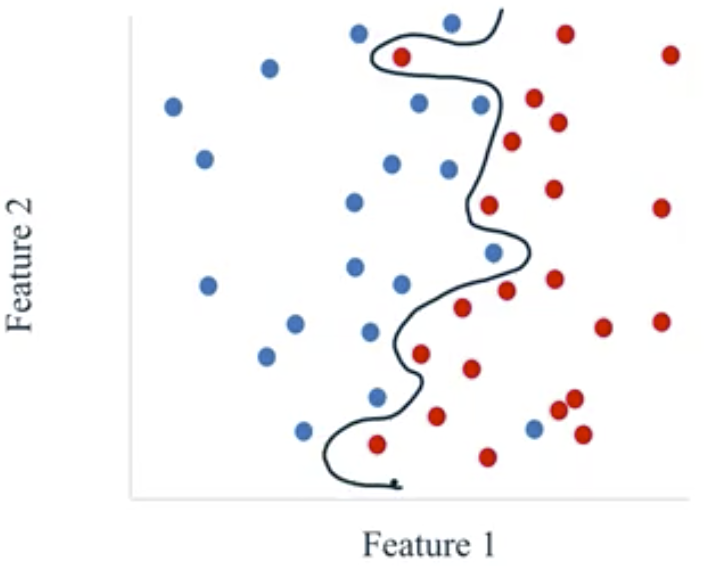
- Underfit: models that are too simple and therefore not likely to generalize well to new examples. These models do not perform well on the training data or on the test data.
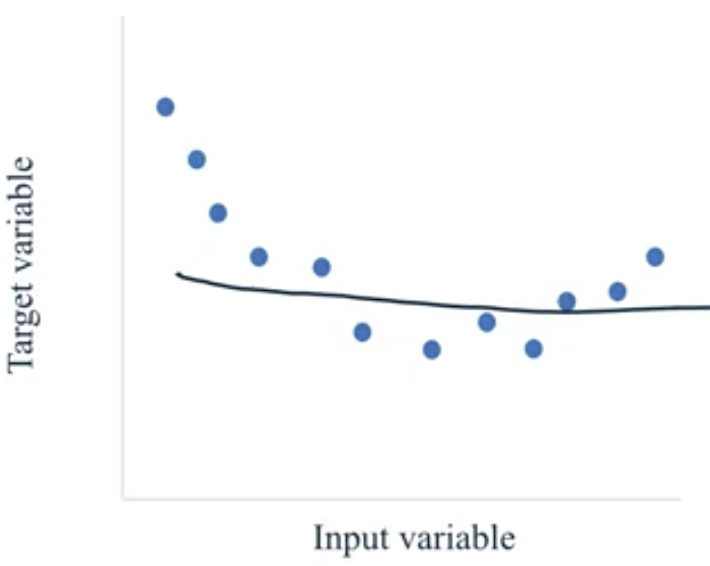
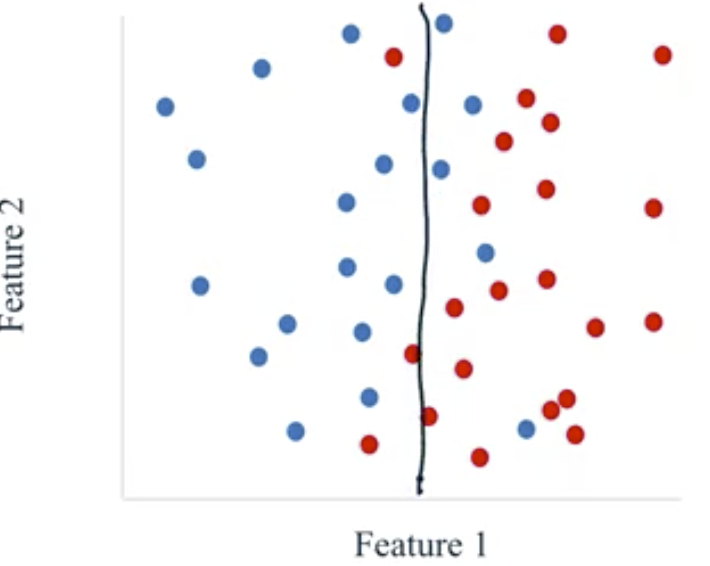
- Fit: a model that captures the general trend of the points while also ignoring the little variations that might exist due to noise.
These notes were taken from the Coursera course Applied Machine Learning in Python. The information is presented by Kevyn Collins-Thompson, PhD, an associate professor of Information and Computer Science at the University of Michigan.