Machine Learning Basics
Machine Learning is the study of computer programs (algorithms) that can learn by example. These ML algorithms can generalize from existing examples of a task. For example, after seeing a training set of labeled images, an impact classifier can figure out how to label new, previously unseen images.
Machine Learning is a necessary technology in areas where traditional computer programming using rules and logic are untenable approaches. Speech and image recognition are two such areas. The basic problem of machine learning is to explore how computers can program themselves to perform a task, and to improve their performance automatically as they gain more experience.
Machine Learning brings together statistics, computer science, and a domain of application.
Statistical Methods enable one to
- Infer conclusions from data and
- Estimate the reliability of predictions.
Computer Science principles are necessary for the development of
- Large-scale computing architectures that are necessary to run large-scale machine learning,
- Algorithms for capturing, manipulating, indexing, combining, retrieving, and performing predictions on data, and
- Software pipelines that manage the complexity of multiple subtasks.
Domains of Application might include Economics, Biology, or Pyschology. Questions that must be answered when using ML in a particular domain include:
- How can an individual or system efficiently improve their performance in a given environment?
- What is learning and how can it be optimized?
Machine Learning for Fraud Detection
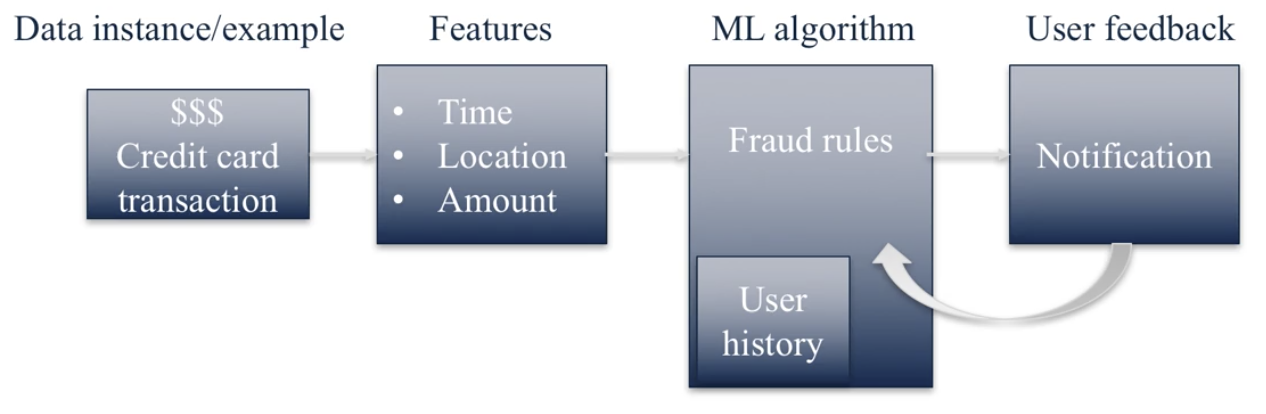
Machine learning is used to detect fraud in credit card transactions. If the time, location, and amount of the transactions are not consistent with your previous purchase patterns, then the ML algorithm may flag the transaction as fraud. The system also keeps track of whether or not the transaction actually was fraudulent, and is thereby able to improve its accuracy over time.
Other Examples
Other examples of areas where Machine Learning is applied include:
- Recommendation systems, such as those on Netflix and Amazon,
- Search engines, which track data about how the user interacts with the site, such as which links are clicked and how long pages are read, and the previously mentioned
- Speech recognition and
- Image recognition.
For a while now, 85% of United States Postal Service mail has been sorted automatically using machine learning. There are also several exciting advancements in the medical domain where image recognition is being used to classify cancer cells as malignant or benign and to find tumors in medical images.
The course on which these notes are based is called “Applied” Machine Learning because it focuses on the application and interpretation the results of machine learning at a high level, without much focus on the technical details.
Key Concepts
Machine Learning problems fall into two main types: Supervised and Unsupervised.
Supervised: Learn to predict target values from labelled data. Supervised learning consists of:
- Classification (target values are discrete classes) and
- Regression (target values are continuous values)
A training set in Supervised Learning consists of a set of labeled pairs $(X, Y)$ where $X$ is the sample data and $Y$ is the target value or label. These training labels are usually provided by human judges, typically provided by crowdsource platforms. The labels may also be gathered implicitly. For example, if a person spends a certain amount of time on a webpage then the system may deduce that the page had been relevant to the user’s search.
Unsupervised: Find useful structure or knowledge in unlabeled data. Unsupervised learning consists of:
- Clustering (finding groups of similar instances in the data) and
- Outlier Detection (finding unusual patterns)
Basic Machine Learning Workflow
The basic machine learning project workflow consists of three basic decisions performed in sequence.

- Select a Representation: a feature representation of the object of interest and selecting a classifier to use.
- Select an Evaluation: a criterion to determine what distinguishes a good from a bad classifier.
- Select an Optimization: select a means of searching for the parameters that result in the best classifier for this evaluation criterion.
The first step consists of converting the problem into a representation that a computer can deal with. First, each input object, also called a sample, is turned into a set of features that describe it. For example, an email may be represented as a list of words with their frequency counts, a picture may be represented as a matrix of color values (pixesl), or an animal may be represented as a set of attribute values. This is also known as feature engineering or feature extraction. Second, a learning model is selected. Each model has tradeoffs in terms of their accuracy, interpretability, speed, etc.
The process of addressing a machine learning task is a cycle that involves iteratively working steps 1, 2, and 3, above. Based on results, changes may be made to features, models, optimization methods, etc.
Basic Python Libraries for Machine Learning
Scikit-Learn is the most widely used Python library for machine learning. It is an open source project that is under ongoing development and improvement. It supports a wide array of machine learning algorithms, and has an active user community.
SciPy and NumPy are two other Python scientific computing libaries that Scikit-Learn relies on. SciPy supports data manipulation and analysis methods that are commonly used in scientific computing, including support for statistical distributions, function optimization, linear algebra, many specialized mathematical functions, and sparse matrices.
NumPy is a Python libary for scientific computing that has support for some fundamental data structures used that scikit-learn uses, including multi-dimensional arrays.
Pandas is a python library for data manipulation and analysis. It includes support for DataFrames, which are similar to Numpy Arrays except that the columns can be type-specific. Pandas also supports reading and writing data to CSV and SQL.
Matplotlib is a widely used Python 2D plotting library that can produce high quality figures in various formats. In particular, the Matplotlib.pyplot library is useful since it can create histograms, bar charts, error charts, and scatter plots with just a few lines of code.