VC Dimensions
This is a continuation of my notes on Computational Learning Theory.
One caveat mentioned at the end of that lecture series was that the formula for the lower sample complexity bound breaks down in the case of an infinite hypothesis space. That formula follows. In particular, as $|H| \rightarrow \infty$, $m \rightarrow \infty$.
$$m \geq \frac{1}{\epsilon}(ln|H| + ln \frac{1}{\delta})$$
This is problematic because each of the following hypothesis spaces are infinite: linear separators, artificial neural networks, and decision trees (continuous inputs). An example of a finite hypothesis space is a decision tree (discrete inputs)
Example 1
Inputs, $X:\ \lbrace1,2,3,4,5,6,7,8,9,10\rbrace$
Hypotheses, $h(x)=x \geq \theta$, where $\theta \in \mathbb R$, so $|H|=\infty$
Syntactic hypothesis space: all the things you could write.
Semantic hypothesis space: the actual different functions you are practically representing. IE, meaningfully different.
So, the hypothesis space for this example is syntactically infinite but semantically finite. This is because we can arrive at the same answer as tracking an infinite number of hypotheses by only tracking non-negative integers ten or below.
Power of a Hypothesis Space
What is the largest set of inputs that the hypothesis class can label in all possible ways?
Consider the set of inputs $S=\lbrace 6 \rbrace$. This hypothesis class can be labeled in all possible ways (either True or False) with different values of $\theta$ assigned.
Consider the larger set of inputs $S=\lbrace 5, 6 \rbrace$ There are four ways this hypothesis class could be labeled {(False, False), (False, True), (True, False), (True, True)}. In practice only 3 of these four are accessible because there is not a $\theta$ that is less than 5 and greater than 6.
The technical term for “labeling in all possible ways” is to “shatter” the input space.
The size of that input space is called the VC dimension, where VC stands for Vapnik-Chervonenkis. In this example, size of the largest set of inputs this hypothesis class can shatter is 1 element.
Example 2
Inputs: $X=\mathbb R$
Hypothesis Space: $H=\lbrace h(x)=x\in [a,b]\rbrace$ where the space is parametrized by $a,b \in \mathbb R$
Based on the figure below, the VC dimension is clearly greater than or equal to 2.
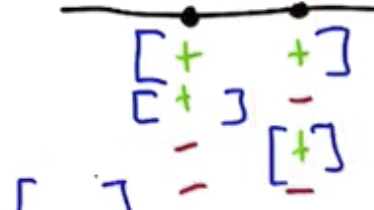
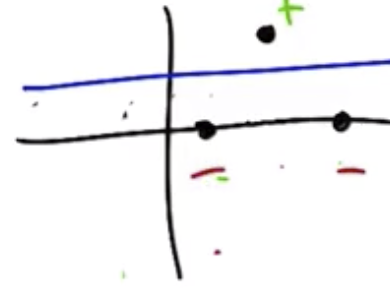
Based on the figure below, the VCC dimensions is clearly less than 3, so the VC dimension is 2.

To show the VC dimension is at least a given number, it is only necessary to find one example that can be shattered. However, to show the VC dimension is less than a given number, it is necessary to prove there are no examples with that can be shattered.
Example 3
Inputs: $X=\mathbb R^2$
Hypothesis Space: $H=\lbrace h(x)=W^T x \geq \theta\rbrace$
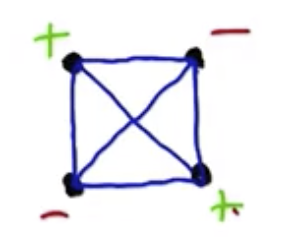
Based on the example below, the VC dimension is at least 3, because lines can be drawn to categorize the points in all possible ways.
Once there are four inputs, however, separating the points becomes impossible.
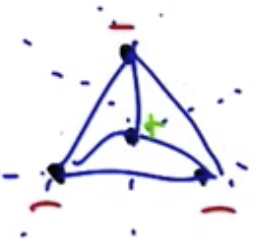
Summarizing the examples outlined above:
| Hypothesis Class Dimension | VC Dimension | Actual Parameters |
|---|---|---|
| 1-D | 1 | $\theta$ |
| interval | 2 | a,b |
| 2-D | 3 | $w_1$, $w_2$, $\theta$ |
The VC dimension is often the number of parameters. For a d-dimensional hyperplane, the parameter count must be d+1.
Sample Complexity and VC Dimensions
If the training data has at least $m$ samples, then that will be sufficient to get $\epsilon$ error with probability $\delta$, where $VC(H)$ is the VC dimension of the hypothesis class.
Infinite case: $$m \geq \frac{1}{\epsilon}(8VC(H) \log_2 \frac{13}{\epsilon}+4\log_2 \frac{2}{\delta})$$
Finite case: $$m \geq \frac{1}{\epsilon}(ln|H| + ln \frac{1}{\delta})$$
What is VC-Dimension of a finite H?
Let $d$ equal the VC dimension of some finite hypothesis $H$: $d = VC(H)$. This implies that there exists $s^d$ distinct concepts, because each gets a different hypothesis. It follows that $2^d \leq |H|$, by manipulation $d \leq \log_2 |H|$.
From similar reasoning we get the following theorem. H is PAC-learnable if and only if the VC dimension is finite.
So, something is PAC-learnable if it has a finite VC dimension. Inversely, something with infinite VC dimension cannot be learned.
The VC dimension captures in one quantity the notion of PAC-Learnability.
For Fall 2019, CS 7461 is instructed by Dr. Charles Isbell. The course content was originally created by Dr. Charles Isbell and Dr. Michael Littman.