Measuring Uncertainty and Information Gain
The Information Edge
Acquiring and maintaining an informational edge should be an important goal for any 21st century company. It is advantageous to be able to quantify how much information is actually gained, whether that information is based upon learning a new fact, purchasing a database, or developing a machine learning forecasting system, etc. This “quantification” of information would make it easier to assign a dollar value to these types of investments. This note will focus on methods for quantifying the actual reduction in uncertainty or informational content for those types of analytics investments.
Probability and Entropy
Probability and Entropy are two different, but related, measures of uncertainty that are used in applied data analysis. Probability can be defined as a measure of degree of belief about the truth of a statement. By convention, probability is written $p(x_{i})$, and is always a real number between 0 and 1. $p(A) = 1$ means a statement is true with certainty, $p(A) = 1$ means a statement is false with certainty.
Probability distributions are collections of individual probabilities that sum to 1. A very simple example is pictured above.
Entropy, written as $H(x)$, is a measure of the uncertainty of the whole probability distribution measured in bits of information. One bit of information is defined as the amount of information required to communicate a single binary choice (0 or 1). Entropy is calculated as follows.
$$H(x) = \sum_{i=1}^n p_i log_2 \frac{1}{p_i}$$
In the case of the coin toss:
$$H(x) = .5 * log_2 \frac{1}{.5} + .5 * log_2 \frac{1}{.5} = log_2 \frac{1}{.5}$$
$$H(x) = log_2 \frac{1}{.5} = log_2 2 = 1$$
In the case of a fair, six-sided die:
$$H(x)=6 ( \frac{1}{6} * log_2 \frac{1}{1 / 6} ) = log_2 6 = 2.58$$
The math works out such that entropy is maximized when there is no basis to choose between the alternatives. If there is a uniform distribution with $n$ possible outcomes, the entropy is equal to $log\ n$. After the coin has been thrown and the outcome is known, the probability goes to 1 and the entropy goes to 0.
Entropy Example
A simple way to conceptualize information encoding in bits is to consider a guessing game where the goal is to converge on an unknown number by asking whether the number is within a certain range. If the number being guessed is 31 and the range is 1 through 50, the most direct way to proceed is to task if the number is greater than 25. No. Greater than 38? No. And so on. 6 “bits” of information will be required to converge onto 31.
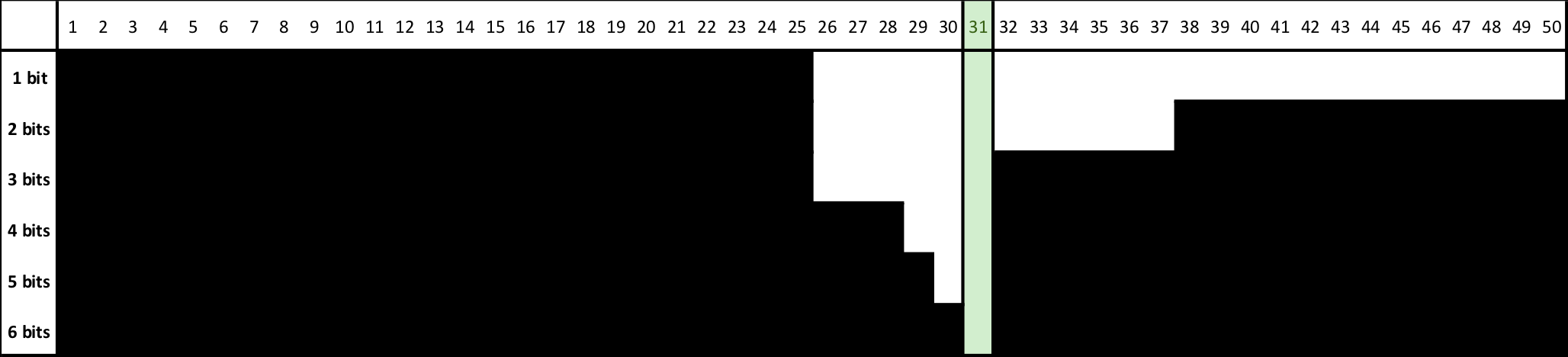
The number of guesses required to converge on one number, if the initial range is $n$, is calculated as follows. On average, it will take 5.6 guesses. Or, 5.6 bits of information are required.
$$bits\ required = log_{2}\ n$$
$$bits\ required = log_{2}\ 50 = 5.643856$$
This is also referred to as the “amount of information gained” once the number has been determined. Or, equivalently, the amount of uncertainty associated with an unknown number in the range 1 through 50.
Joint Entropy
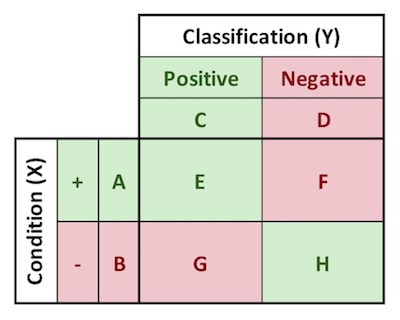
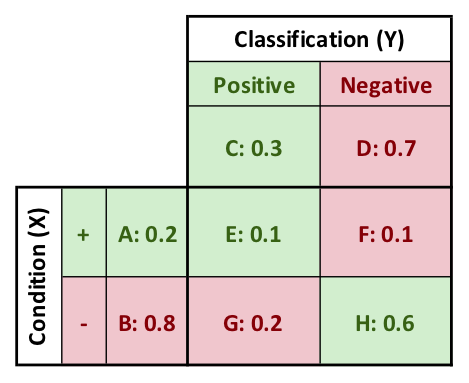
The confusion matrix is used to define joint and conditional probabilities. E, F, G, and H in the image below are the joint probabilities of the conditions (X) and the classifications (Y). The joint distribution of $P(X,Y)$ is E, F, G, and H.
Similarly, we can define the joint entropy of X and Y, written as $H(X,Y)$ or $H(E,F,G,H)$.
Recall that the true positive rate is defined as follows:
$$True\ Positive\ Rate\ = \frac{E}{A}$$
This is the conditional probability of having a positive test given than you are positive for the condition.
Similarly, the concept of conditional entropy can be defined as follows:
$$H(X|Y)=P(Y=Y_1)H(X|Y=Y_1)+P(Y=Y_2)H(X|Y=Y_2)$$
As a specific example:
$$H(+|POS)=CH(\frac{E}{C},\frac{G}{C})+DH(\frac{F}{D},\frac{H}{D})$$
Dependence and Mutual Information
When given two different probability distributions, the relationship between the entropy values dictates the amount of “mutual information.” If the two probability distributions are independent, the Venn diagram shown below will not intersect, and there will be no mutual information.
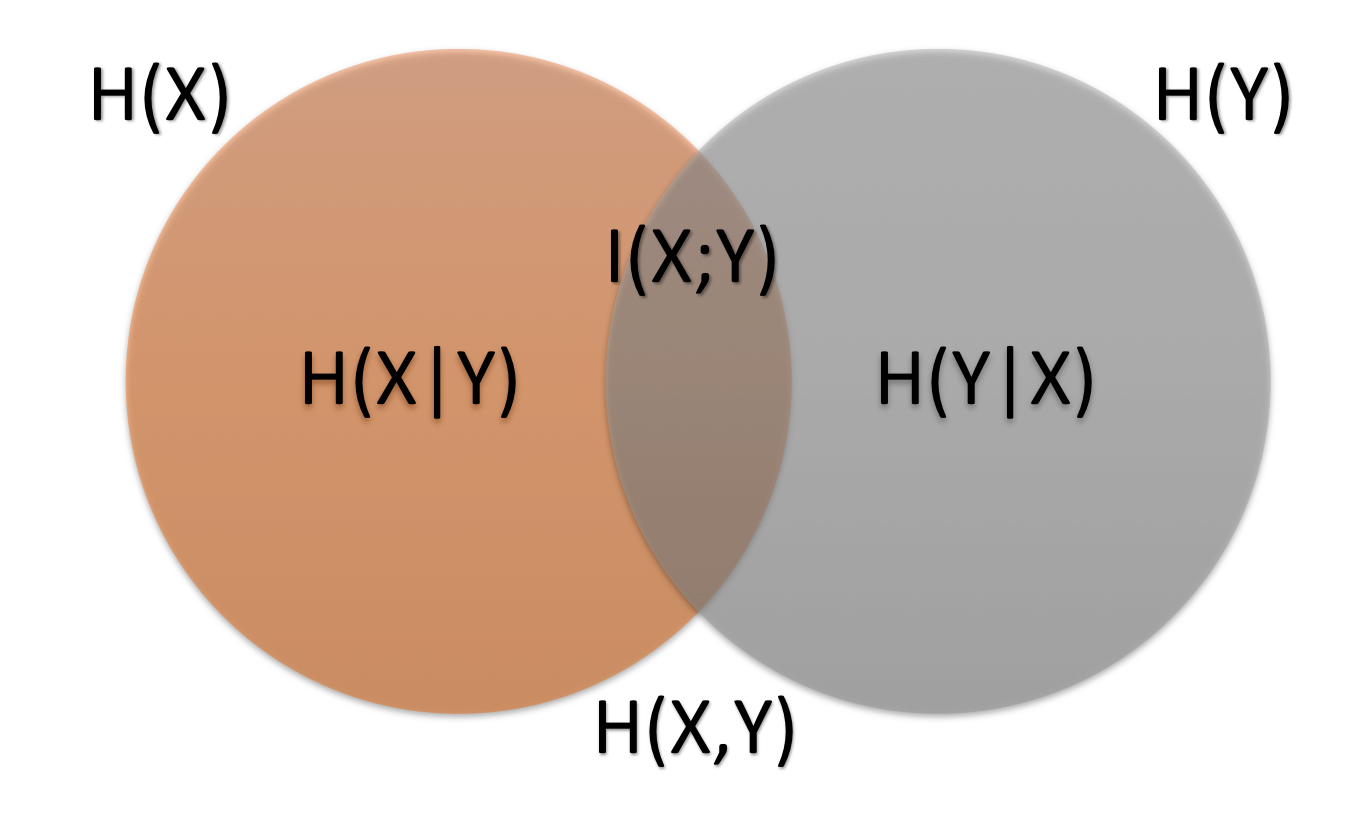
Independence is defined, technically, as the condition where the joint distribution is equal to the product distribution. This is the situation described as
$$P(X,Y)=P(X)P(Y)$$
Alternatively, it can also be defined as the situation where the mutual information is equal to 0. If and only if the mutual information is zero, the following relationships will hold. Reference the confusion matrix for the meanings of the terms.
$$E=AC,\ F=AD,\ G=BC,\ H=BD$$
The mutual information, $I(X,Y)$, is important to us because it represents how much “carry over” there is between the observable (classification, $Y$) and the unobservable (condition, $X$). The mutual information is measured by first measuring the uncertainty that there initially is around the condition $X$, and then subtracting the remaining uncertainty after learning $Y$. The mutual information is expressed as the relative entropy of joint and product distributions. Formulaically, this is written as
$$I(X,Y) = H(X)-H(X|Y)$$
A Numerical Example
Professor Egger presents this example in his Information-Gain-Calculator.xlsx spreadsheet. The goal is to work from a confusion matrix to a Percentage Information Gain (P.I.G.), which is the average reduction in uncertainty of one outcome in condition (X) upon learning one outcome in classification (Y).
Note that only three pieces of information are needed in order to generate everything that follows. These three pieces of information are:
- Incidence of Positive Condition (A): 0.2
- Incidence of Positive Classification (C): 0.3
- Count of True Positives (E): 0.1
Using this information, the following confusion matrix is generated.
$$H(X)=Alog_2\ \frac{1}{A}\ +\ Blog_2\ \frac{1}{B}$$
$$=0.464+0.258=0.722$$
$$H(Y)=Clog_2\ \frac{1}{C}\ +\ Dlog_2\ \frac{1}{D}$$
$$=0.521+0.360=0.881$$
$$H(Y|X)=AH(\frac{E}{A},\frac{F}{A})+DH(\frac{G}{B},\frac{H}{B})$$
$$= 0.200 * 1.000 + .800 * .811 = .849$$
$$H(X|Y)=CH(\frac{E}{C},\frac{G}{C})+DH(\frac{F}{D},\frac{H}{D})$$
$$= 0.300 * 0.918 + .700 * .592 = 0.690$$
There are at least three ways of calculating the mutual information. The third way involves calculating directly from the parameters in the confusion matrix, and so allows for avoiding the calculating the conditional entropies independently. As expected, they each produce the same results.
$$I(X;Y)=H(X)-H(X|Y)=0.722-0.690=0.032$$
$$I(X;Y)=H(Y)-H(Y|X)=0.881-0.849=0.032$$
$$I(X;Y)=Elog_2\ \frac{E}{AC}\ +\ Flog_2\ \frac{F}{AD}\ +\ Glog_2\ \frac{G}{BC}\ +\ Hlog_2\ \frac{H}{BD}$$
$$=0.074-0.046-0.0526+0.060=0.032$$
Now the Percentage Information Gain (P.I.G.) can be calculated as
$$P.I.G.= \frac{I(X;Y)}{H(X)}=\frac{0.032}{0.722}=4.5%$$
The interpretation of this number, once again, is the average reduction in uncertainty of one condition (X) incidence upon learning one classification (Y) incidence.
A Conceptual Example
In the gameshow “Let’s Make a Deal,” Monty Hall presents the show contestants with three doors, behind one of which is a prize. The probability distribution and the entropy thereof are as follows.
$$P(X)=P(\frac{1}{3},\frac{1}{3},\frac{1}{3})$$
$$H(X) = \sum_{i=1}^n p_i log_2 \frac{1}{p_i}$$
$$=\frac{1}{3}\ log_2 3\ +\ \frac{1}{3}\ log_2 3\ +\ \frac{1}{3}\ log_2\ 3 = log_2 3 = 1.59\ bits$$
The contestants initially choose one door, but it is not opened. Then, Monty Hall opens one of the two remaining doors that does not have the prize behind it, effectively eliminating it as a possibility. The contestant then is given the opportunity to switch to the final remaining door, or to stay with their initial choice. The probability effects are counter-intuitive, but they actually change to the following, where the $2/3$ probability is the final, third door.
$$P(X|Y)=P(\frac{1}{3},\frac{2}{3})$$
The entropy becomes
$$H(X|Y)=\frac{1}{3}\ log_2 3\ +\ \frac{2}{3}\ log_2 \frac{3}{2} = 0.92\ bits$$
Where $Y$ is the information revealed by Monty Hall. Recall also:
$$I(X;Y)=H(X)-H(X|Y)=1.59-0.92=0.67\ bits$$
$$P.I.G. = \frac{I(X;Y)}{H(X)} = \frac{0.67}{1.59} = 42.1%$$
Monty Hall has provided the contestant 42.1% of the information required to have certainty about where the prize is.
Similar Example
Reconsidering the same problem with 5 doors, and with Monty Hall opening two after the contestant selects one.
$$P(X)=(\frac{1}{5},\frac{1}{5},\frac{1}{5},\frac{1}{5},\frac{1}{5})$$
$$H(X)=log_2 5=2.32\ bits$$
$$P(X|Y)=(\frac{1}{5},\frac{2}{5},\frac{2}{5})$$
$$H(X|Y)=\frac{1}{5}log_2 5+\frac{2}{5}log_2 \frac{5}{2}+\frac{2}{5}log_2 \frac{5}{2}$$
$$=\frac{1}{5}(2.32)+\frac{2}{5}(1.32)+\frac{2}{5}(1.32)=1.52\ bits$$
$$I(X;Y)=H(X)-H(X|Y)=2.32-1.52=0.80\ bits$$
Derivation of Bayes' Theorem
Bayes' Theormem is a formula that describes the probability of an event based on knowledge of conditions that might be related to the event. The starting point for its derivation is
$$P(A,B)=P(A|B)P(B)$$
This is read as, the probability of A, given B, times the probability of B, equals the probability of A and B. First, by symmetry, note that:
$$P(A,B)=P(B,A)$$
Further, by symmetry to the first statement:
$$P(B,A)=P(B|A)P(A)$$
Dividing both sides by $P(A)$:
$$P(B|A)=\frac{P(B,A)}{P(A)}$$
By symmetry again:
$$P(B|A)=\frac{P(A,B)}{P(A)}$$
Substituting the first equation and completing the derivation:
$$P(B|A)=\frac{P(A|B)P(B)}{P(A)}$$
Bayes' Theorem, stated above, is a powerful tool for turning data into knowledge. Entropy is the measure used to quantify how much is learned from the data, and Bayes' Theorem does the work. Bayes' Theorem and entropy operate on probability distributions, which can be thought of as carriers of information. According to Egger:
“Bayes' Theorem does the work; entropy keeps score.”
An Example of Inverse Probability
Consider a hypothetical situation where a person has a coin that is either a 50-50, fair coin, or a 60-40 (heads-tails), crooked coin. The person flips the coin, and either heads or tails are observed. The task is to quantify how much has been learned by observing the result of the flip. This will be quantified in terms of the amount of uncertainty reduction. This type of problem is called an “inverse probability problem,” and it makes use of Bayes' Theorem.
A few definitions:
- A: “The coin comes up tails.”
- ~A: “The coin comes up heads.”
- B: “The coin is fair.”
- ~B: “The coin is crooked.”
At the start, we know a few things:
$$P(Y=B)=.5, P(Y=\sim B)=.5$$
$$P(X=A|Y=B)=.5, P(X=A|Y=\sim B)=.4$$
$$P(X=A|Y=B)P(Y=B)=P(X=A,Y=B)$$
An additional rule from probability:
$$P(A)=P(A,B)+P(A,\sim B)$$
$$P(A)=P(A|B)P(B)+P(A|\sim B)P(\sim B)=(.5)(.5)+(.4)(.5)=.45$$
$$P(B|A)=\frac{P(A|B)P(B)}{P(A)}=\frac{(.5)(.5)}{.45}=.56$$
$$P(\sim B|A)= \frac{(.4)(.5)}{.45}=.44$$
So, from one observation of tails, we changed the probability from (.5,.5) to (.56,.44). We have learned, from the observation of tails, that the coin is more likely to be fair than crooked.
$$H(.5,.5)-H(X|Y)=H(.5,.5)-H(.56,.44)$$
$$1-.9909=.0091\ bits=.91%$$
Or, almost 1% reduction in uncertainty about which coin is being used, based upon a single coin toss.
Similar Coin Example
- A: “The coin comes up heads.”
- ~A: “The coin comes up tails.”
- B: “The coin is fair.”
- ~B: “The coin is crooked.”
From the prompt:
$$P(B)=.3, P(\sim B)=.7$$
$$P(A|B)=.5, P(A|\sim B)=.4$$
The coin is flipped, coming up heads.
$$P(A)=P(A|B)P(B)+P(A|\sim B)P(\sim B)=(.5)(.3)+(.4)(.7)=.43$$
$$P(B|A)=\frac{P(A|B)P(B)}{P(A)}=\frac{(.5)(.3)}{.43}=.35$$
Thus, given the new information in the form of the coin flip, the new probability that the coin is fair is 0.35.
Similar Dice Example
- A: “The die comes up three.”
- ~A: “The die comes up other than three.”
- B: “The die is fair.”
- ~B: “The die is unfair.”
$$P(Y=B)=.5, P(Y=\sim B)=.5$$
$$P(A|B)=.17, P(A|\sim B)=.33$$
The die is rolled, coming up three.
$$P(A)=P(A|B)P(B)+P(A|\sim B)P(\sim B)=(.17)(.5)+(.33)(.5)=.25$$
$$P(B|A)=\frac{P(A|B)P(B)}{P(A)}=\frac{(.17)(.5)}{.25}=.34$$
Thus, given the new information in the form of the die role, the new probability that the die is fair is 0.34.
Information-Gain-Calculator.xlsx
Some other content is taken from my notes on other aspects of the aforementioned Coursera course.