Web Scraping Salesforce Tables
It is easy to forget that Salesforce renders all of its information in HTML tables, just like any other webpage. This means that it is easy to web scrape the information from Salesforce tables that are visible in the browser, instead of doing an export of the data.
As a practical example, we can scrape the fields names, labels, and datatypes that are available at: Setup » Object Manager » Select an Object » Fields & Relationships.
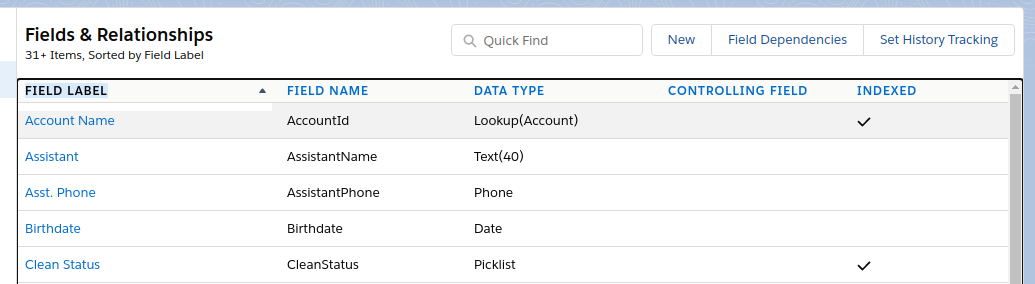
- First, navigate to the page that has the data. It may be necessary to scroll all the way to the bottom of the page to get all the data rendered into the table.
- Then, in Chrome, select an element on the page that is in the table you want to scrape.
- Right-click the item you selected, then select “Inspect” in the menu.
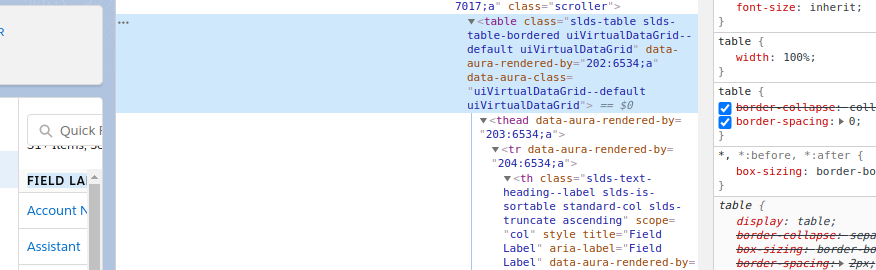
- In the HTML viewer Chrome opens, select the
tableholding the data of interest, right-click on the highlightedtabletag, then select copy » Copy outerHTML. - Paste the HTML into a plain text document and save as a .html file. The first item in the text file should be the HTML tag. It should begin somthing like the following.
<table class="slds-table slds-table-bordered uiVirtualDataGrid--default uiVirtualDataGrid"
...
- Now, the HTML can be parsed and the data inside extracted into Pandas DataFrame then into a CSV or Excel file, as follows. Some of these parameters may need to be changed, depending on the specific table you are trying to parse.
from bs4 import BeautifulSoup
import pandas as pd
def scrape_objects(file_string):
with open(file_string) as file:
soup = BeautifulSoup(file,
"html.parser")
rows = soup.find_all('tr')
header_list = []
for col in rows[0]:
if col != '\n':
header_list.append(col.text.strip().lower())
row_list = []
for row in rows[1:]:
col_list = []
for col in row:
if col != '\n':
col_list.append(col.text.strip())
row_list.append(col_list)
df = (pd.DataFrame(row_list,
columns=header_list)
.drop(columns=['sort indexed','actions','sort controlling field'])
.rename(columns={'sort field labelsorted ascending' : 'label',
'sort field name' : 'name',
'sort data type' : 'type'}))
df.info()
return df
Only the first 31 fields on the Contact object are captured here, because only the first page of contacts was rendered in the browder when I downloaded the HTML.
account = scrape_objects('web-scraping-salesforce-tables/html.html')
account.to_clipboard(index=False)
account
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 31 entries, 0 to 30
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 label 31 non-null object
1 name 31 non-null object
2 type 31 non-null object
dtypes: object(3)
memory usage: 872.0+ bytes
| label | name | type | |
|---|---|---|---|
| 0 | Account Name | AccountId | Lookup(Account) |
| 1 | Assistant | AssistantName | Text(40) |
| 2 | Asst. Phone | AssistantPhone | Phone |
| 3 | Birthdate | Birthdate | Date |
| 4 | Clean Status | CleanStatus | Picklist |
| 5 | Contact Owner | OwnerId | Lookup(User) |
| 6 | Created By | CreatedById | Lookup(User) |
| 7 | Data.com Key | Jigsaw | Text(20) |
| 8 | Department | Department | Text(80) |
| 9 | Description | Description | Long Text Area(32000) |
| 10 | Do Not Call | DoNotCall | Checkbox |
| 11 | |||
| 12 | Email Opt Out | HasOptedOutOfEmail | Checkbox |
| 13 | Fax | Fax | Fax |
| 14 | Fax Opt Out | HasOptedOutOfFax | Checkbox |
| 15 | Home Phone | HomePhone | Phone |
| 16 | Individual | IndividualId | Lookup(Individual) |
| 17 | Languages | Languages__c | Text(100) |
| 18 | Last Modified By | LastModifiedById | Lookup(User) |
| 19 | Last Stay-in-Touch Request Date | LastCURequestDate | Date/Time |
| 20 | Last Stay-in-Touch Save Date | LastCUUpdateDate | Date/Time |
| 21 | Lead Source | LeadSource | Picklist |
| 22 | Level | Level__c | Picklist |
| 23 | Mailing Address | MailingAddress | Address |
| 24 | Mobile | MobilePhone | Phone |
| 25 | Name | Name | Name |
| 26 | Other Address | OtherAddress | Address |
| 27 | Other Phone | OtherPhone | Phone |
| 28 | Phone | Phone | Phone |
| 29 | Reports To | ReportsToId | Lookup(Contact) |
| 30 | Title | Title | Text(128) |