Internal Rate of Return (Unequal Timing) in Python
Setup
from bs4 import BeautifulSoup
import pandas as pd
import numpy as np
import matplotlib.pyplot as pltDefine the Internal Rate of Return (with Unequal Timing) Functions
Taken from https://github.com/waynez/xirr/blob/master/financial.py.
import datetime
from scipy import optimize
def xnpv(rate,cashflows):
chron_order = sorted(cashflows, key = lambda x: x[0])
t0 = chron_order[0][0]
return sum([cf/(1+rate)**((t-t0).days/365.0) for (t,cf) in chron_order])
def xirr(cashflows,guess=0.1):
return optimize.newton(lambda r: xnpv(r,cashflows),guess)Parse and Manipulate Data
Open File
The raw HTML data was taken from the Transactions page on the Fundrise website.
with open('data/fundrise_transactions_201010_1.html') as file:
link_list_html = file.read()
soup = BeautifulSoup(link_list_html,
"html.parser")transactions = soup.find_all('div',
{'class':'transaction-item__expandable-section'})
print(len(transactions))46
Parse Text for Each Transaction
transaction_list = []
for t in transactions:
text = (t
.get_text())
transaction_list.append(text)Add Each Transaction’s Text into a DataFrame
All text for each transaction on one line with tabs and newlines.
transaction_text = pd.DataFrame(transaction_list)
print(transaction_text.shape)
transaction_text.head()(46, 1)
| 0 | |
|---|---|
| 0 | \n\n\n\n\n\t\t\t\t\t\t\tIssued Date\n\t\t\t\t\... |
| 1 | \n\n\n\n\n\t\t\t\t\t\t\tIssued Date\n\t\t\t\t\... |
| 2 | \n\n\n\n\n\t\t\t\t\t\t\tIssued Date\n\t\t\t\t\... |
| 3 | \n\n\n\n\n\t\t\t\t\t\t\tIssued Date\n\t\t\t\t\... |
| 4 | \n\n\n\n\n\t\t\t\t\t\t\tIssued Date\n\t\t\t\t\... |
Remove all headers from the text.
for header in ['Name','Advisory fee','Quantity','Price','Gross dividend',
'Net dividend','Total','Amount','Discount','Bank account',
'Effective date','Issued date','Effective date','Issued date']:
transaction_text[0] = (transaction_text[0]
.str.replace(header,''))Tokenize the text string based on one or more tabs and newlines.
parsed = pd.DataFrame(
transaction_text[0].str.split(r'[\t\n]+',
expand=True))
parsed = (parsed
.drop(columns=[0])
.rename(columns={1:'type'}))
parsed = parsed.replace('',np.nan)
parsed.head()| type | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | ... | 71 | 72 | 73 | 74 | 75 | 76 | 77 | 78 | 79 | 80 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Issued Date | Oct 7, 2020 | Income eREIT | $88.46 | $1.89 | $86.57 | Growth eREIT | $38.34 | $1.94 | $36.40 | ... | None | None | None | None | None | None | None | None | None | NaN |
| 1 | Issued Date | Jul 8, 2020 | Growth eREIT | $8.17 | $1.91 | $6.26 | Income eREIT | $83.31 | $1.86 | $81.45 | ... | None | None | None | None | None | None | None | None | None | NaN |
| 2 | Issued Date | Apr 8, 2020 | Income eREIT | $106.12 | $1.87 | $104.25 | Growth eREIT | $56.21 | $1.91 | $54.30 | ... | None | None | None | None | None | None | None | None | None | NaN |
| 3 | Issued Date | Jan 12, 2020 | Income eREIT | $109.52 | $1.89 | $107.63 | Growth eREIT | $55.29 | $1.76 | $53.53 | ... | None | None | None | None | None | None | None | None | None | NaN |
| 4 | Issued Date | Oct 8, 2019 | Growth eREIT | $56.81 | $1.73 | $55.08 | Income eREIT | $89.43 | $1.89 | $87.54 | ... | None | None | None | None | None | None | None | None | None | NaN |
5 rows × 80 columns
parsed['type'] = (parsed['type']
.replace({'Order #' : 'Purchase',
'Issued Date' : 'Dividend',
'Redemption number' : 'Withdrawal'}))
print(parsed['type'].value_counts())Purchase 25
Dividend 19
Withdrawal 2
Name: type, dtype: int64
Parse into individual transaction types.
d = parsed[parsed['type']=='Dividend'].reset_index(drop=True)
p = parsed[parsed['type']=='Purchase'].reset_index(drop=True)
w = parsed[parsed['type']=='Withdrawal'].reset_index(drop=True)Dividends
Drop Gross Dividend and Advisory Fee columns from d.
for col in range(4,80,4):
d = (d
.drop(columns=[col,col+1]))
d.columns = range(d.shape[1])
d = d.T.dropna(how='all').T
d = d.rename(columns={0:'type',
1:'date'})Stack to create normalized data.
d_stack = pd.DataFrame()
for col in range(2,34,2):
d_stack = (d_stack
.append(d[['type','date',col,col+1]]
.rename(columns={col:'fund',
col+1:'amount'})))
d_stack['date'] = pd.to_datetime(d_stack['date'])
d_stack = (d_stack
.dropna(subset=['amount'])
.drop_duplicates()
.sort_values(['date','fund'])
.reset_index(drop=True))Purchases
p.columns = range(p.shape[1])
p = (p
.drop(columns=[1,2,3,4,5]))
for col in range(8,80,4):
p = p.drop(columns=[col,col+1])
p.columns = range(p.shape[1])
p = p.T.dropna(how='all').T
p = p.rename(columns={0:'type',
1:'date'})Stack to create normalized data.
p_stack = pd.DataFrame()
for col in range(2,38,2):
p_stack = (p_stack
.append(p[['type','date',col,col+1]]
.rename(columns={col:'fund',
col+1:'amount'})))p_stack['date'] = pd.to_datetime(p_stack['date'])
p_stack = (p_stack
.dropna(subset=['amount'])
.drop_duplicates()
.sort_values(['date','fund'])
.reset_index(drop=True))p_stack.head()| type | date | fund | amount | |
|---|---|---|---|---|
| 0 | Purchase | 2016-03-02 | Income eREIT | $1,000.00 |
| 1 | Purchase | 2016-04-07 | Growth eREIT | $1,000.00 |
| 2 | Purchase | 2016-04-22 | Income eREIT | $1,000.00 |
| 3 | Purchase | 2016-09-28 | Growth eREIT | $1,000.00 |
| 4 | Purchase | 2016-09-29 | Growth eREIT | $1,000.00 |
Withdrawals
w.columns = range(w.shape[1])
w = (w
.drop(columns=[1,2,4,6,7,8,10,11,12,13,14])
.rename(columns={0:'type',
3:'date',
5:'fund',
9:'amount'}))
w = w.T.dropna(how='all').Tw_stack = w.copy()
w_stack['date'] = pd.to_datetime(w_stack['date'])
w_stack.head()| type | date | fund | amount | |
|---|---|---|---|---|
| 0 | Withdrawal | 2018-04-29 | Los Angeles eFund | $2,425.00 |
| 1 | Withdrawal | 2018-04-29 | Washington DC eFund | $2,425.00 |
Current Value
From Estimated Value of Shares on 10/10/2020
c = pd.DataFrame([('Growth eREIT', '$5,332.65'),
('Income eREIT', '$5,332.65'),
('East Coast eREIT', '$4,004.94'),
('West Coast eREIT', '$3,017.11'),
('Heartland eREIT', '$2,968.83'),
('Income eREIT II', '$1,029.73'),
('Los Angeles eFund', '$571.24'),
('Washington DC eFund', '$531.79'),
('Growth eREIT III', '$264.39'),
('Income eREIT III', '$206.83'),
('National eFund', '$108.29'),
('Fundrise iPO', '$3,190.00')],
columns=['fund','amount'])
c['type'] = 'Current Value'
c['date'] = pd.to_datetime('2020-10-10')
c.head()| fund | amount | type | date | |
|---|---|---|---|---|
| 0 | Growth eREIT | $5,332.65 | Current Value | 2020-10-10 |
| 1 | Income eREIT | $5,332.65 | Current Value | 2020-10-10 |
| 2 | East Coast eREIT | $4,004.94 | Current Value | 2020-10-10 |
| 3 | West Coast eREIT | $3,017.11 | Current Value | 2020-10-10 |
| 4 | Heartland eREIT | $2,968.83 | Current Value | 2020-10-10 |
Combine in to Single Transactions Dataset
t = (d_stack
.append(p_stack)
.append(w_stack)
.append(c)
.sort_values(['date','fund'])
.reset_index(drop=True))
t['amount'] = (t['amount']
.str.replace('$','')
.str.replace(',','')
.astype(float))
t.loc[t['type']=='Purchase','amount'] = -1*t['amount']Write to file for quick reference later.
t.to_csv('cleansed_transactions.csv')t[t['fund']=='Income eREIT'].tail()| type | date | fund | amount | |
|---|---|---|---|---|
| 134 | Dividend | 2020-01-12 | Income eREIT | 107.63 |
| 142 | Dividend | 2020-04-08 | Income eREIT | 104.25 |
| 149 | Dividend | 2020-07-08 | Income eREIT | 81.45 |
| 157 | Dividend | 2020-10-07 | Income eREIT | 86.57 |
| 166 | Current Value | 2020-10-10 | Income eREIT | 5332.65 |
Calculate Internal Rate of Return of Funds
returns = []
for fund in t['fund'].unique():
cashflows = t[t['fund']==fund][['date','amount']].to_numpy()
r = round(xirr(cashflows,guess=0.1)*100,1)
returns.append((fund,r))returns = (pd.DataFrame(returns,
columns=['fund','irr'])
.sort_values('irr',
ascending=False)
.reset_index(drop=True))
current_value = (t[t['type']=='Current Value'][['fund','amount']]
.rename(columns={'amount':'current value'}))
returns = pd.merge(returns, current_value,
on=['fund'],
how='outer')
cost_basis = (t[t['type']=='Purchase'][['fund','amount']]
.rename(columns={'amount':'cost basis'})
.groupby('fund')
.sum()
.reset_index())
cost_basis['cost basis'] *= -1
dividends = (t[t['type']=='Dividend'][['fund','amount']]
.rename(columns={'amount':'dividends'})
.groupby('fund')
.sum()
.reset_index())
withdrawals = (t[t['type']=='Withdrawal'][['fund','amount']]
.rename(columns={'amount':'withdrawals'})
.groupby('fund')
.sum()
.reset_index())
first_purchase = (t[t['type']=='Purchase'][['fund','date']]
.rename(columns={'date':'first purchase'})
.groupby('fund')
.min()
.reset_index())
last_purchase = (t[t['type']=='Purchase'][['fund','date']]
.rename(columns={'date':'last purchase'})
.groupby('fund')
.max()
.reset_index())
returns = pd.merge(returns, cost_basis,
on=['fund'],
how='outer')
returns = pd.merge(returns, withdrawals,
on=['fund'],
how='outer')
returns['appreciation'] = returns['cost basis'] - returns['withdrawals'].fillna(0)
returns['appreciation'] = returns['current value'] - returns['appreciation']
returns['appreciation'] = returns['appreciation'].round(2)
returns = pd.merge(returns, dividends,
on=['fund'],
how='outer')
for col in ['current value', 'cost basis', 'withdrawals', 'appreciation', 'dividends']:
returns[col] = returns[col].round(0)
returns = returns.fillna('')
for col in ['current value', 'cost basis', 'appreciation']:
returns[col] = returns[col].astype(int)
returns = pd.merge(returns, first_purchase,
on=['fund'],
how='outer')
returns = pd.merge(returns, last_purchase,
on=['fund'],
how='outer').fillna('')
returns| fund | irr | current value | cost basis | withdrawals | appreciation | dividends | first purchase | last purchase | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Growth eREIT | 13.1 | 5333 | 4001 | 1331 | 891 | 2016-04-07 | 2019-06-18 | |
| 1 | East Coast eREIT | 11.5 | 4005 | 3470 | 535 | 744 | 2016-10-24 | 2019-06-18 | |
| 2 | Income eREIT | 10.2 | 5333 | 5014 | 318 | 1596 | 2016-03-02 | 2019-04-25 | |
| 3 | Income eREIT III | 9.7 | 207 | 205 | 2 | 24 | 2019-04-22 | 2019-06-27 | |
| 4 | Income eREIT II | 8.0 | 1030 | 1028 | 2 | 116 | 2019-04-17 | 2019-04-25 | |
| 5 | West Coast eREIT | 6.7 | 3017 | 3017 | 0 | 670 | 2016-10-25 | 2019-06-18 | |
| 6 | Heartland eREIT | 5.4 | 2969 | 3017 | -48 | 582 | 2016-10-25 | 2019-06-18 | |
| 7 | Growth eREIT III | 5.2 | 264 | 253 | 11 | 8 | 2019-04-22 | 2019-06-18 | |
| 8 | National eFund | 3.2 | 108 | 104 | 4 | 2019-06-14 | 2019-06-27 | ||
| 9 | Fundrise iPO | -0.0 | 3190 | 3190 | 0 | 2017-02-10 | 2019-03-25 | ||
| 10 | Los Angeles eFund | -0.8 | 571 | 3024 | 2425 | -28 | 2017-08-18 | 2019-06-18 | |
| 11 | Washington DC eFund | -2.0 | 532 | 3024 | 2425 | -67 | 2017-08-18 | 2019-06-18 |
Decision
cashflows = t[['date','amount']].to_numpy()
r = round(xirr(cashflows,guess=0.1)*100,1)
print('All Funds IRR to Date: {}%'.format(r))All Funds IRR to Date: 8.1%
irr_threshold_to_liquidate = 7plt.figure(figsize=(11,8.5))
barlist = plt.bar(returns['fund'],
returns['irr'])
plt.xticks(rotation=20)
for spine in plt.gca().spines.values():
spine.set_visible(False)
for bar in barlist[5:]:
bar.set_color('#ff7f0e')
plt.axhline(irr_threshold_to_liquidate,
color='k',
linewidth=1)
plt.title('Keep the Funds in Blue');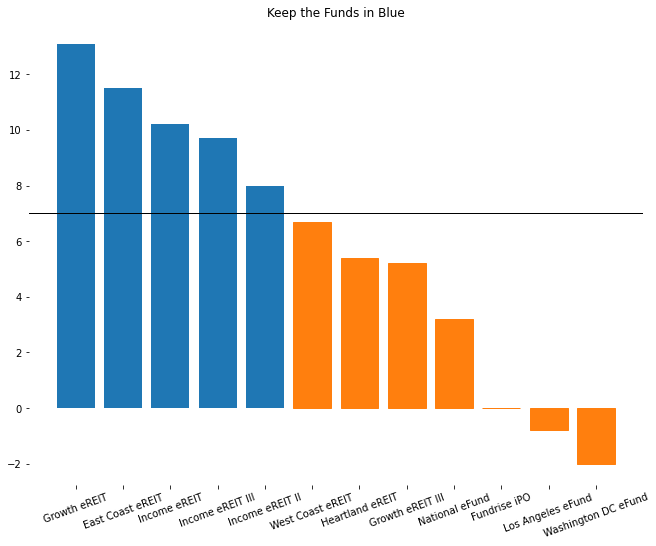
funds_to_retain = returns[(returns['irr']>irr_threshold_to_liquidate)&
(returns['fund']!='Fundrise iPO')].copy()
print('Total Amount to Retain: $ {}'.format(funds_to_retain['current value'].sum()))
print(' Fundrise iPO: $ {}'.format((returns[returns['fund']=='Fundrise iPO']
['current value'].to_numpy()[0])))
cashflows = t[t['fund'].isin(funds_to_retain['fund'])][['date','amount']].to_numpy()
r = round(xirr(cashflows,guess=0.1)*100,1)
print(' Retained Funds IRR: {}%'.format(r))
funds_to_retainTotal Amount to Retain: $ 15908
Fundrise iPO: $ 3190
Retained Funds IRR: 11.4%
| fund | irr | current value | cost basis | withdrawals | appreciation | dividends | first purchase | last purchase | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | Growth eREIT | 13.1 | 5333 | 4001 | 1331 | 891 | 2016-04-07 | 2019-06-18 | |
| 1 | East Coast eREIT | 11.5 | 4005 | 3470 | 535 | 744 | 2016-10-24 | 2019-06-18 | |
| 2 | Income eREIT | 10.2 | 5333 | 5014 | 318 | 1596 | 2016-03-02 | 2019-04-25 | |
| 3 | Income eREIT III | 9.7 | 207 | 205 | 2 | 24 | 2019-04-22 | 2019-06-27 | |
| 4 | Income eREIT II | 8.0 | 1030 | 1028 | 2 | 116 | 2019-04-17 | 2019-04-25 |
funds_to_liquidate = returns[(returns['irr']<irr_threshold_to_liquidate)&
(returns['fund']!='Fundrise iPO')].copy()
print('Total Amount to Liqudate: $ {}'.format((funds_to_liquidate['current value']
.sum()
.round(2))))
cashflows = t[t['fund'].isin(funds_to_liquidate['fund'])][['date','amount']].to_numpy()
r = round(xirr(cashflows,guess=0.1)*100,1)
print(' Liquidated Funds IRR: {}%'.format(r))
funds_to_liquidateTotal Amount to Liqudate: $ 7461
Liquidated Funds IRR: 4.1%
| fund | irr | current value | cost basis | withdrawals | appreciation | dividends | first purchase | last purchase | |
|---|---|---|---|---|---|---|---|---|---|
| 5 | West Coast eREIT | 6.7 | 3017 | 3017 | 0 | 670 | 2016-10-25 | 2019-06-18 | |
| 6 | Heartland eREIT | 5.4 | 2969 | 3017 | -48 | 582 | 2016-10-25 | 2019-06-18 | |
| 7 | Growth eREIT III | 5.2 | 264 | 253 | 11 | 8 | 2019-04-22 | 2019-06-18 | |
| 8 | National eFund | 3.2 | 108 | 104 | 4 | 2019-06-14 | 2019-06-27 | ||
| 10 | Los Angeles eFund | -0.8 | 571 | 3024 | 2425 | -28 | 2017-08-18 | 2019-06-18 | |
| 11 | Washington DC eFund | -2.0 | 532 | 3024 | 2425 | -67 | 2017-08-18 | 2019-06-18 |