Unsupervised Learning
Unsupervised learning involves understanding how to group data when either:
- no labels are available to predict. Consider algorithms used to look at brain scans for areas that raise concern. Labels are unavailable, but it is possible to determine which areas are most similar or different from one another.
- the goal is to group data, not predict a label. This is often the case when tons of data is available and it needs to be condensed down to a smaller number of features to be used.
There are two popular methods for unsupervised machine learning:
- Clustering: groups data together based on similarities.
- Dimensionality Reduction: condenses a large number of features into a much smaller set of features.
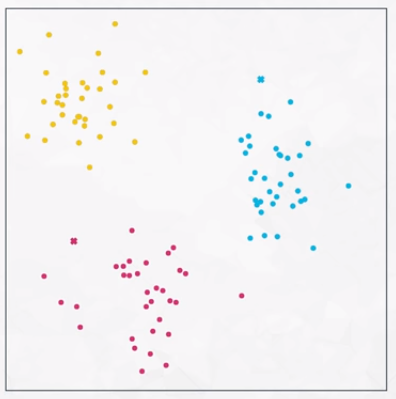
Clustering Example

The data in the image above can reasonably be grouped as shown in the following image.
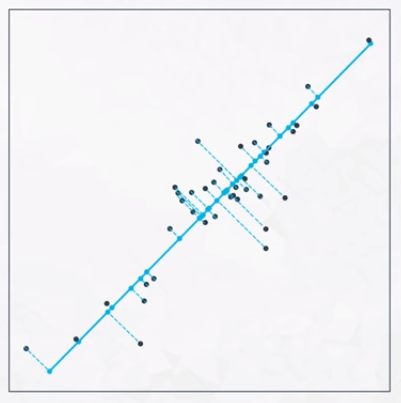
Dimensionality Reduction Example

In the case of the image above, the data appear to follow a specific pattern. We can reduce the data from two dimensions to one.
Topics
Here are the specific unsupervised learning topics:
- Clustering: Clustering is among the most popular approaches to unsupervised learning. The k-means algorithm will be reviewed in particular.
- Hierarchical and Density Based Clustering: This is another set of clustering algorithms takes an approach of using density based “closeness” measures. In particular, this can be used in traffic classification and anomaly detection.
- Gaussian Mixture Models and Cluster Validation: This is another “distance-based” technique that is similar to the Density Based Clustering methods in the last section.
- Principal Component Analysis: This is one of the most popular decomposition methods today. It relies on matrix decomposition methods, which are different from the density-based methods in previous sections.
- Random Projection and Independent Component Analysis: uses independent component analysis, a third way to decompose data.
This content is taken from notes I took while pursuing the Intro to Machine Learning with Pytorch nanodegree certification.