Inference and Validation
Inference, a term borrowed from statistics, is the process of using a trained model to make making predictions. However, neural networks have a tendency to perform too well on the training data and aren’t able to generalize to data that hasn’t been seen before. This is called overfitting and it impairs inference performance.
To test for overfitting while training, we measure the performance on data not in the training set called the validation set. We avoid overfitting through regularization such as dropout while monitoring the validation performance during training.
Let’s start by loading the dataset through torchvision. This time we’ll be taking advantage of the test set which you can get by setting train=False here:
testset = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/',
download=True,
train=False,
transform=transform)
The test set contains images just like the training set. Typically you’ll see 10-20% of the original dataset held out for testing and validation with the rest being used for training.
import torch
from torchvision import datasets, transforms
# Define a transform to normalize the data
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))])
# Download and load the training data
trainset = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/',
download=True,
train=True,
transform=transform)
trainloader = torch.utils.data.DataLoader(trainset,
batch_size=64,
shuffle=True)
# Download and load the test data
testset = datasets.FashionMNIST('~/.pytorch/F_MNIST_data/',
download=True,
train=False,
transform=transform)
testloader = torch.utils.data.DataLoader(testset,
batch_size=64,
shuffle=True)
Use the same model as was used in the classifying fashion mnist example.
from torch import nn
model = nn.Sequential(nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1))
The goal of validation is to measure the model’s performance on data that isn’t part of the training set. Performance here is up to the developer to define. Typically this is just accuracy, the percentage of classes the network predicted correctly. Other options are precision and recall and top-5 error rate. This example focuses on accuracy.
images, labels = next(iter(testloader))
# Flatten MNIST images into a 784 long vector
images = images.view(images.shape[0], -1)
As explected, below, there are 10 class probabilities for 64 examples, as expected.
# Get the class probabilities
ps = torch.exp(model(images))
print(ps.shape)
torch.Size([64, 10])
With the probabilities, we can get the most likely class using the ps.topk method. This returns the $k$ highest values.
Since we just want the most likely class for each of the 64 examples, we can use ps.topk(1). This returns a tuple of the top-$k$ values and the top-$k$ indices. If the highest value is the fifth element, we’ll get back 4 as the index.
As shown, there is a prediction for each of the 64 examples.
top_p, top_class = ps.topk(1, dim=1)
print(str(top_class.shape) + '\n')
print(top_class[:5,:])
torch.Size([64, 1])
tensor([[9],
[9],
[9],
[9],
[9]])
Now we can check if the predicted classes match the labels. This is simple to do by equating top_class and labels, but we have to be careful of the shapes. Here top_class is a 2D tensor with shape (64, 1) while labels is 1D with shape (64).
To get the equality to work out the way we want, top_class and labels must have the same shape.
If we do
equals = top_class == labels
equals will have shape (64, 64). What it’s doing is comparing the one element in each row of top_class with each element in labels which returns 64 True/False boolean values for each row.
equals = top_class == labels.view(*top_class.shape)
Now we need to calculate the percentage of correct predictions. equals has binary values, either 0 or 1. This means that if we just sum up all the values and divide by the number of values, we get the percentage of correct predictions. This is the same operation as taking the mean, so we can get the accuracy with a call to torch.mean. If only it was that simple. If you try torch.mean(equals), you’ll get an error
RuntimeError: mean is not implemented for type torch.ByteTensor
This happens because equals has type torch.ByteTensor but torch.mean isn’t implemented for tensors with that type. So we’ll need to convert equals to a float tensor. Note that when we take torch.mean it returns a scalar tensor, to get the actual value as a float we’ll need to do accuracy.item().
accuracy = torch.mean(equals.type(torch.FloatTensor))
print(f'Accuracy: {accuracy.item()*100}%')
Accuracy: 6.25%
The network is untrained so it’s making random guesses and we should see an accuracy around 10%. Now let’s train our network and include our validation pass so we can measure how well the network is performing on the test set. Since we’re not updating our parameters in the validation pass, we can speed up our code by turning off gradients using torch.no_grad():
# turn off gradients
with torch.no_grad():
# validation pass here
for images, labels in testloader:
...
Training
Print Total Accuracy for Each Validation Loop
The following is a helper function to show losses and accuracies over the course of training.
%matplotlib inline
import matplotlib.pyplot as plt
def plot_losses_and_accuracies(train_losses, test_losses, accuracies, title):
fig, (ax1, ax2) = plt.subplots(figsize=(12,6), ncols=2)
plt.suptitle(title)
ax1.set_title('Losses')
ax1.set_ylim(0,1)
ax1.plot(train_losses, label='Training loss')
ax1.plot(test_losses, label='Validation loss')
ax1.legend(frameon=False)
ax2.set_title('Accuracy')
ax2.set_ylim(0,1)
ax2.plot(accuracies, label='Accuracy')
The following is a helper function that performs the actual training.
from torch import optim
def train_model(model, optimizer_str):
criterion = nn.NLLLoss()
if optimizer_str == 'SGD':
optimizer = optim.SGD(model.parameters(),
lr=0.003)
elif optimizer_str == 'Adam':
optimizer = optim.Adam(model.parameters(),
lr=0.003)
epochs = 50
print("\tepoch\ttrain_loss\ttest_loss\taccuracy")
train_losses, test_losses, accuracies = [], [], []
for epoch in range(epochs):
running_loss, test_loss, accuracy = 0, 0, 0
for images, labels in trainloader:
# Flatten MNIST images into a 784 long vector
images = images.view(images.shape[0], -1)
optimizer.zero_grad()
log_ps = model(images)
loss = criterion(log_ps, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# Turn off gradients for validation, saves memory and computations
with torch.no_grad():
# Turn off dropout for validation
model.eval()
for images, labels in testloader:
# Flatten MNIST images into a 784 long vector
images = images.view(images.shape[0], -1)
log_ps = model(images)
test_loss += criterion(log_ps, labels)
ps = torch.exp(log_ps)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor))
# Turn on dropout for validation
model.train()
train_losses.append(running_loss/len(trainloader))
test_losses.append(test_loss/len(testloader))
accuracy = accuracy.item()/len(testloader)
accuracies.append(accuracy)
if epoch == 0 or (((epoch+1) % 10) == 0):
print("\t{:5}\t{:10.3}\t{:9.3}\t{:8.3}".format(epoch+1,
train_losses[-1],
test_losses[-1],
accuracies[-1]))
plot_losses_and_accuracies(train_losses,
test_losses,
accuracies,
optimizer_str)
Adam Optimizer
from torch import nn
model_1 = nn.Sequential(nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1))
train_model(model_1, optimizer_str = 'Adam')
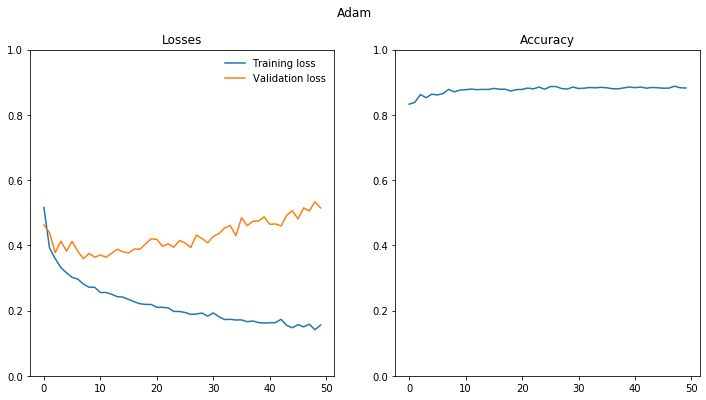
epoch train_loss test_loss accuracy
1 0.516 0.462 0.833
10 0.271 0.364 0.876
20 0.219 0.42 0.877
30 0.183 0.408 0.885
40 0.162 0.488 0.886
50 0.156 0.515 0.882
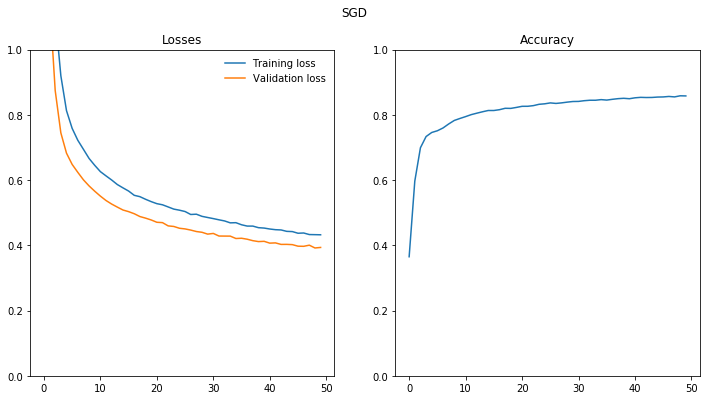
SGD Optimizer
model_2 = nn.Sequential(nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1))
train_model(model_2, optimizer_str = 'SGD')
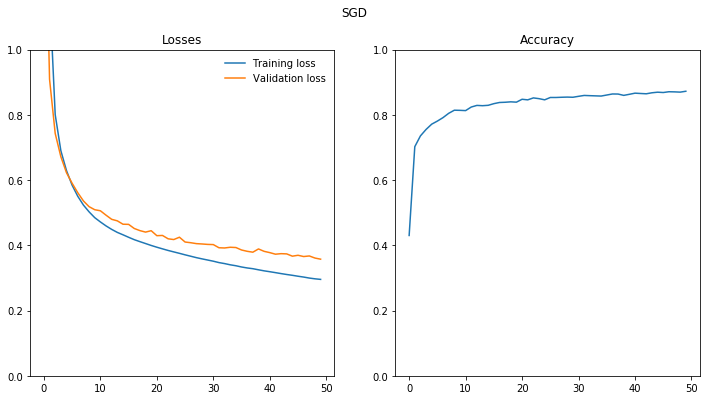
epoch train_loss test_loss accuracy
1 2.09 1.64 0.43
10 0.485 0.509 0.814
20 0.4 0.445 0.839
30 0.355 0.403 0.854
40 0.322 0.382 0.863
50 0.296 0.358 0.872
Overfitting
If we look at the training and validation losses as we train the network, we can see a phenomenon known as overfitting.
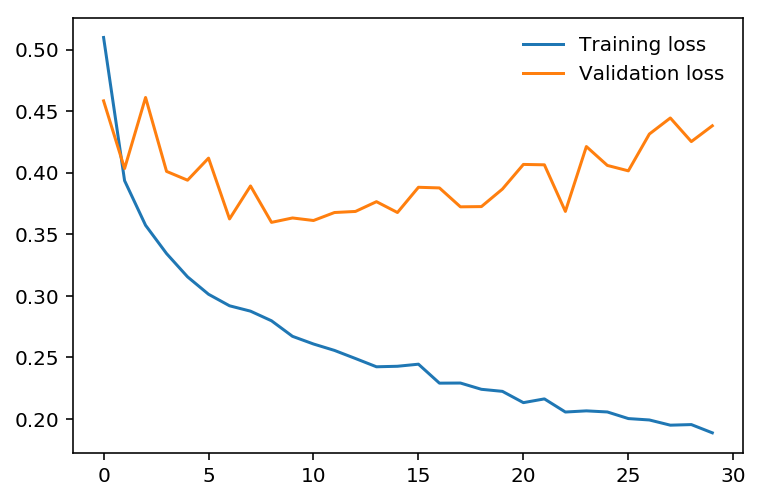
The network learns the training set better and better, resulting in lower training losses. However, it starts having problems generalizing to data outside the training set leading to the validation loss increasing. The ultimate goal of any deep learning model is to make predictions on new data, so we should strive to get the lowest validation loss possible.
One option is to use the version of the model with the lowest validation loss, here the one around 8-10 training epochs. This strategy is called early-stopping. In practice, you’d save the model frequently as you’re training then later choose the model with the lowest validation loss.
The most common method to reduce overfitting (outside of early-stopping) is dropout, where we randomly drop input units. This forces the network to share information between weights, increasing it’s ability to generalize to new data. Adding dropout in PyTorch is straightforward using the nn.Dropout module.
class Classifier(nn.Module):
def __init__(self):
super().__init__()
self.fc1 = nn.Linear(784, 256)
self.fc2 = nn.Linear(256, 128)
self.fc3 = nn.Linear(128, 64)
self.fc4 = nn.Linear(64, 10)
# Dropout module with 0.2 drop probability
self.dropout = nn.Dropout(p=0.2)
def forward(self, x):
# make sure input tensor is flattened
x = x.view(x.shape[0], -1)
# Now with dropout
x = self.dropout(F.relu(self.fc1(x)))
x = self.dropout(F.relu(self.fc2(x)))
x = self.dropout(F.relu(self.fc3(x)))
# output so no dropout here
x = F.log_softmax(self.fc4(x), dim=1)
return x
During training we want to use dropout to prevent overfitting, but during inference we want to use the entire network. So, we need to turn off dropout during validation, testing, and whenever we’re using the network to make predictions. To do this, you use model.eval(). This sets the model to evaluation mode where the dropout probability is 0. You can turn dropout back on by setting the model to train mode with model.train(). In general, the pattern for the validation loop will look like this, where you turn off gradients, set the model to evaluation mode, calculate the validation loss and metric, then set the model back to train mode.
# turn off gradients
with torch.no_grad():
# set model to evaluation mode
model.eval()
# validation pass here
for images, labels in testloader:
...
# set model back to train mode
model.train()
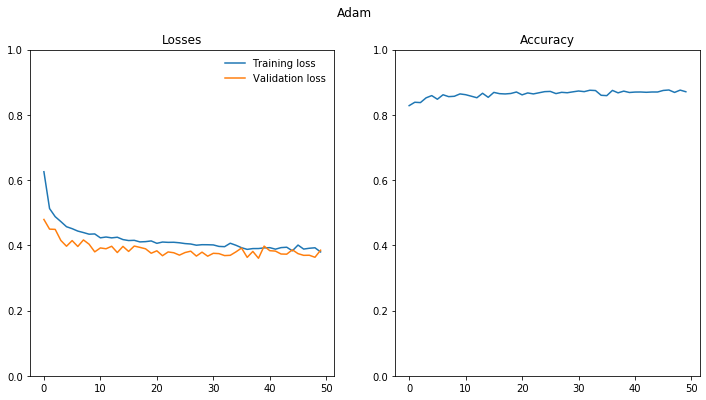
Add Dropout
Note the overfitting is reduced if not eliminated.
Adam Optimizer
dropout_model_1 = nn.Sequential(nn.Dropout(0.2),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1))
train_model(dropout_model_1, optimizer_str = 'Adam')
epoch train_loss test_loss accuracy
1 0.626 0.479 0.828
10 0.435 0.38 0.864
20 0.413 0.376 0.87
30 0.402 0.367 0.871
40 0.392 0.398 0.869
50 0.38 0.385 0.871
SGD Optimizer
dropout_model_2 = nn.Sequential(nn.Dropout(0.2),
nn.Linear(784, 256),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(256, 128),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(128, 64),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(64, 10),
nn.LogSoftmax(dim=1))
train_model(dropout_model_2, optimizer_str = 'SGD')
epoch train_loss test_loss accuracy
1 2.2 1.92 0.365
10 0.645 0.566 0.789
20 0.534 0.478 0.823
30 0.485 0.434 0.841
40 0.453 0.412 0.85
50 0.432 0.394 0.858
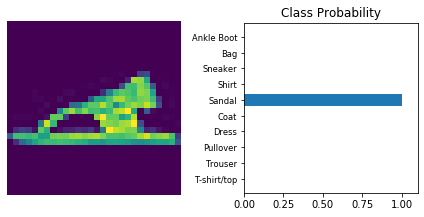
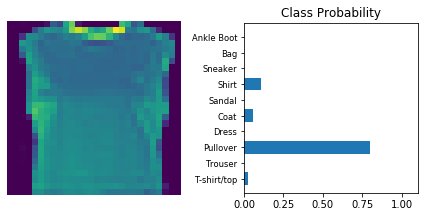
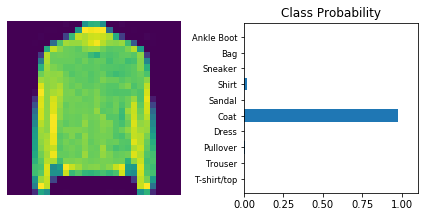
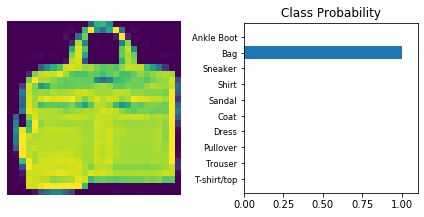
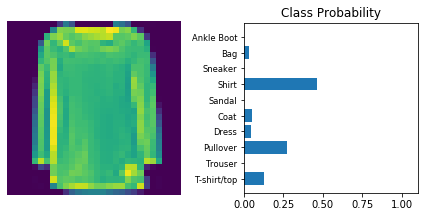
Inference
Now that the model is trained, it can be used for inference. We need to set the model in inference mode with model.eval() and turn off autograd with the torch.no_grad() context.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
def view_classify(img, ps):
ps = ps.data.numpy().squeeze()
fig, (ax1, ax2) = plt.subplots(figsize=(6,9), ncols=2)
ax1.imshow(img.resize_(1, 28, 28).numpy().squeeze())
ax1.axis('off')
ax2.barh(np.arange(10), ps)
ax2.set_aspect(0.1)
ax2.set_yticks(np.arange(10))
ax2.set_yticklabels(['T-shirt/top',
'Trouser',
'Pullover',
'Dress',
'Coat',
'Sandal',
'Shirt',
'Sneaker',
'Bag',
'Ankle Boot'], size='small');
ax2.set_title('Class Probability')
ax2.set_xlim(0, 1.1)
plt.tight_layout()
Use model trained with dropout and the ‘Adam’ optimizer.
dropout_model_1.eval()
dataiter = iter(testloader)
for _ in range(10):
images, labels = dataiter.next()
img = images[0]
# Convert 2D image to 1D vector
img = img.view(1, 784)
# Calculate the class probabilities (softmax) for img
with torch.no_grad():
output = dropout_model_1.forward(img)
ps = torch.exp(output)
# Plot the image and probabilities
view_classify(img.view(1, 28, 28), ps)



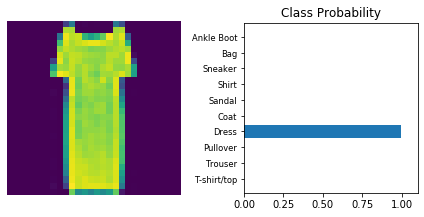
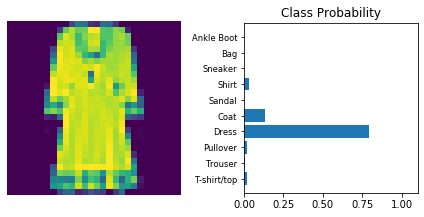
Copyright © 2018 Udacity